编译流水线--- V8 引擎解析与编译
延迟解析:V8 是如何实现闭包的?
在编译阶段,V8 不会对所有代码进行编译,采用一种“惰性编译”或者“惰性解析”,也就是说 V8 默认不会对函数内部的代码进行编译,只有当函数被执行前,才会进行编译。
闭包的问题指的是:由于子函数使用到了父函数的变量,导致父函数在执行完成以后,它内部被子函数引用的变量无法及时在内存中被释放。
而闭包问题产生的根本原因是 JavaScript 中本身的特性:
- 可以在函数内部定义新的函数
- 内部函数可以访问父函数的变量
- 函数是一等公民,所以函数可以作为返回值
既然由于JavaScript 的这种特性就会出现闭包的问题,那么就需要解决闭包问题,“预编译“ 或者 “预解析” 就出现了
预编译具体方案: 在编译阶段,V8 会对函数函数进行预解析
- 判断函数内语法是否正确
- 子函数是否引用父函数中的变量,如果有的话,将这个变量复制一份到堆中,同时子函数本身也是一个对象,也会被放到堆中
- 父函数执行完成后,内存会被释放
- 子函数在执行时,依然可以从堆内存中访问复制过来的变量
字节码(一):V8 为什么又重新引入字节码?
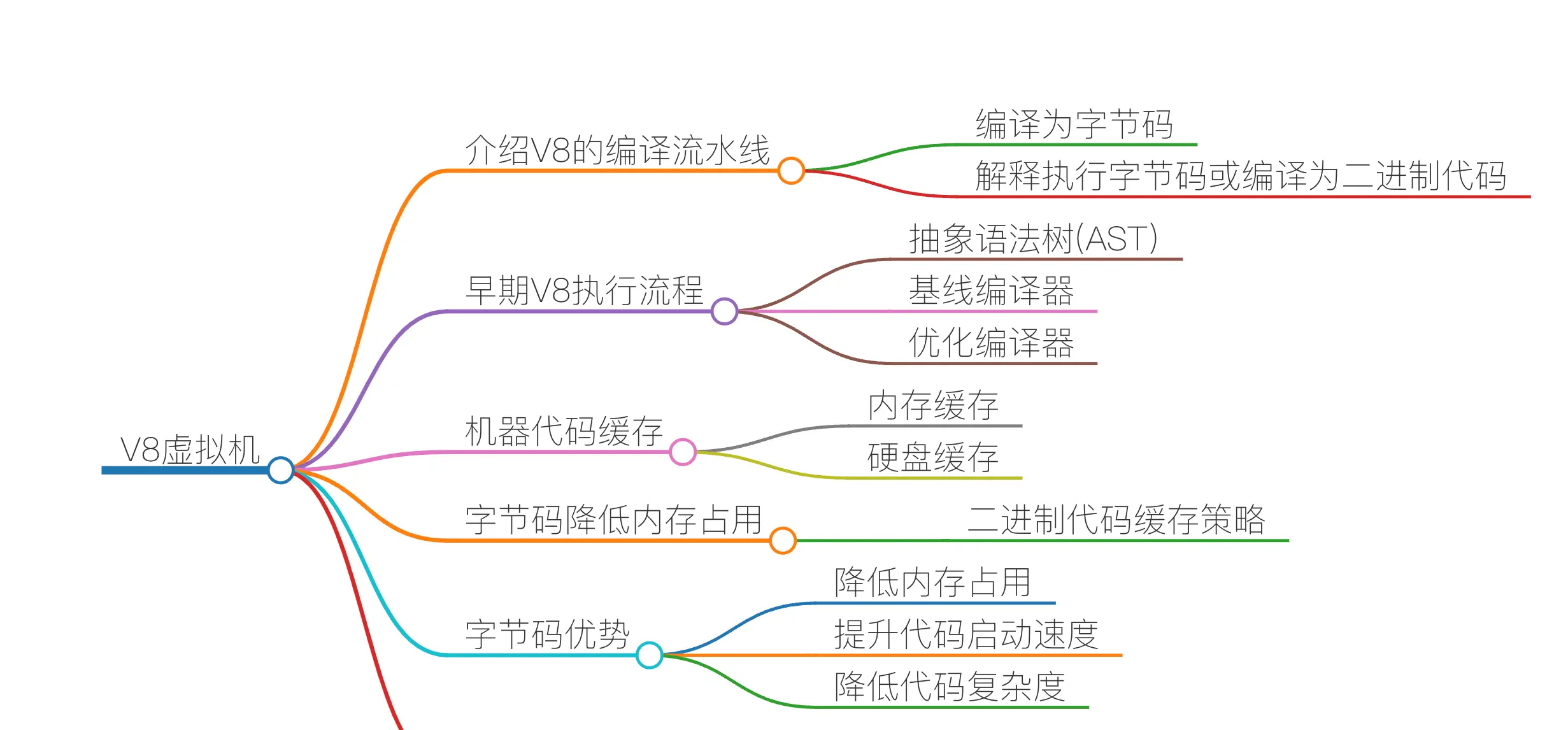
在 V8 中,字节码有两个作用:
- 解释器可以直接执行字节码
- 优化编译器可以将字节码编译为机器码,然后再执行机器码
早期的 V8
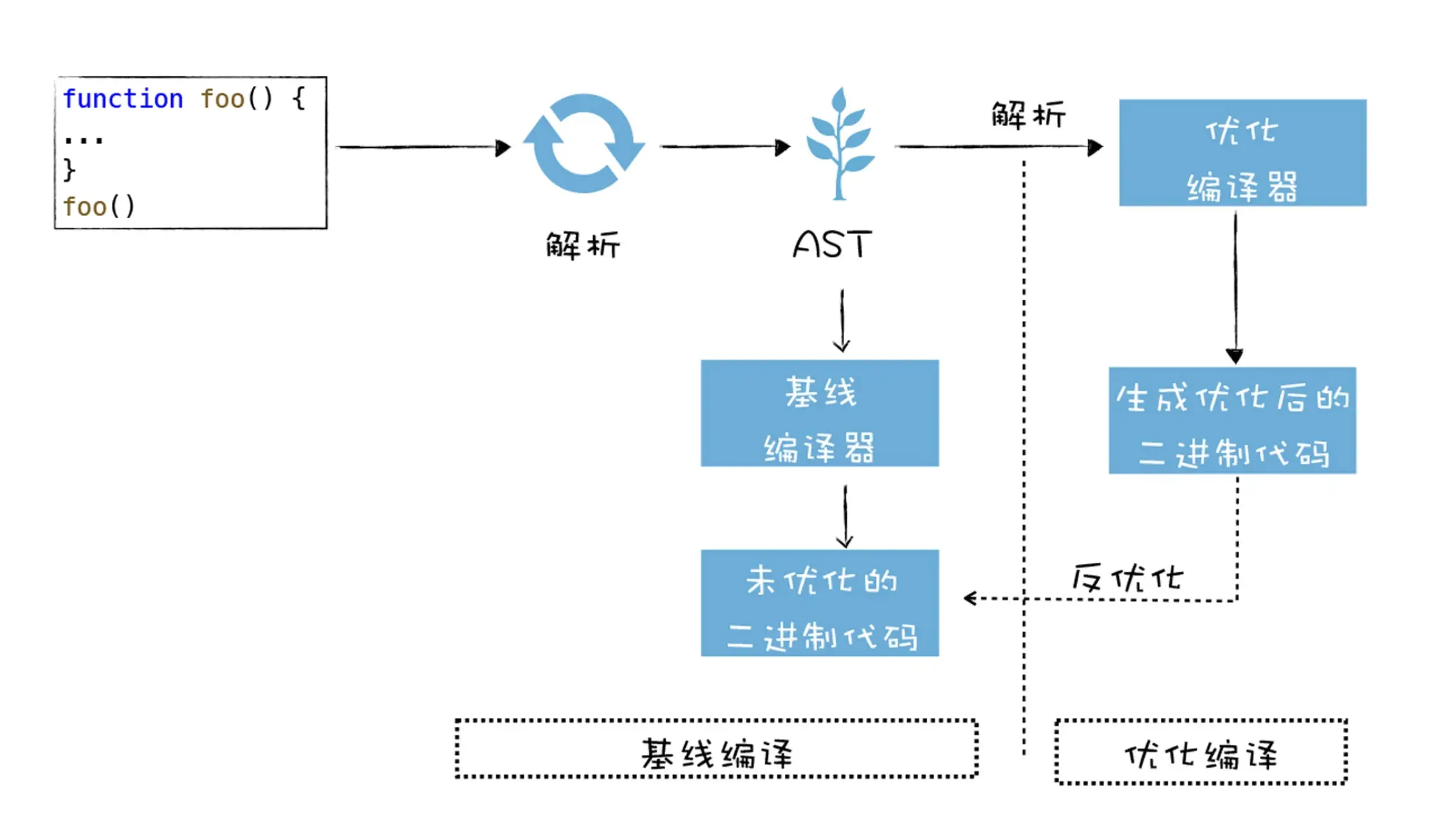
V8团队认为“先生成字节码再执行字节码”,会牺牲代码的执行速度,便直接将JavaScript代码编译成机器码
使用了两个编译器:
- 基线编译器:将 JavaScript 代码编译为没有优化过的机器码
- 优化编译器:将一些热点代码(执行频繁的代码)优化为执行效率更高的机器码
执行 JavaScript:
- 将 JavaScript代码转换为抽象语法树(AST)
- 基线编译器将AST编译为未优化过的机器码,然后V8执行这些未优化过的机器代码
- 在执行未优化的机器代码时,将一些热点代码优化为执行效率更高的机器代码,然后执行优化过的机器码
- 如果优化过的机器码不满足当前代码的执行,V8会进行反优化操作
问题
- 机器码缓存
V8执行一段JavaScript代码,编译时间和执行时间差不多
如果再JavaScript没有改变的情况下,每次都编译这段代码,就会浪费CPU资源
所以V8引入机器码缓存:
- 将源代码编译成机器码后,放在内存中(内存缓存)
- 下次再执行这段代码,就先去内存中查找是否存在这段代码的机器码,有的话就执行这段机器码
- 将编译后的机器码存入硬盘中,关闭浏览器后,下次重新打开,可以直接用编译好的机器码
时间缩短了20% ~ 40%
这是用空间换时间的策略,在移动端非常吃内存
- 惰性编译
V8采用惰性编译,只会编译全局执行上下文的代码
由于ES6之前,没有块级作用域,为了实现各模块之间的隔离,会采用立即执行函数
这会产生很多闭包,闭包模块中的代码不会被缓存,所以只缓存顶层代码是不完美的
所以V8就进行了大重构
如:
(function () {
// 模块内部的代码
})();这样可以创建一个独立的作用域,避免模块之间的变量污染。
但是,这种做法会产生大量的闭包。闭包是指一个函数能够访问其外部函数作用域中的变量,即使外部函数已经执行完毕。
在上面的例子中,模块内部的代码都是闭包,它们都能访问模块作用域中的变量。
问题在于,V8 引擎在进行代码优化和缓存的时候,只会缓存顶层的代码,而不会缓存闭包中的代码。
也就是说,即使模块中的大部分代码都是相同的,只要有一部分代码被包裹在闭包中,那么这些闭包中的代码就不会被缓存。这就导致了性能的下降。
现在的 V8
字节码 + 解释器 + 编译器
5K 的源代码 JavaScript -> 40K 字节码 -> 10M 的机器码字节码的体积远小于机器码,浏览器就可以实现缓存所有的字节码,而不仅仅是全局执行上下文的字节码
优点:
- 降低了内存
- 提升代码启动速度
- 降低了代码的复杂度
缺点:
执行效率下降
解释器的作用是将源代码转换成字节码
V8 的解释器是:lgnition;V8 的编译器是:TurboFan
如何降低代码复杂度
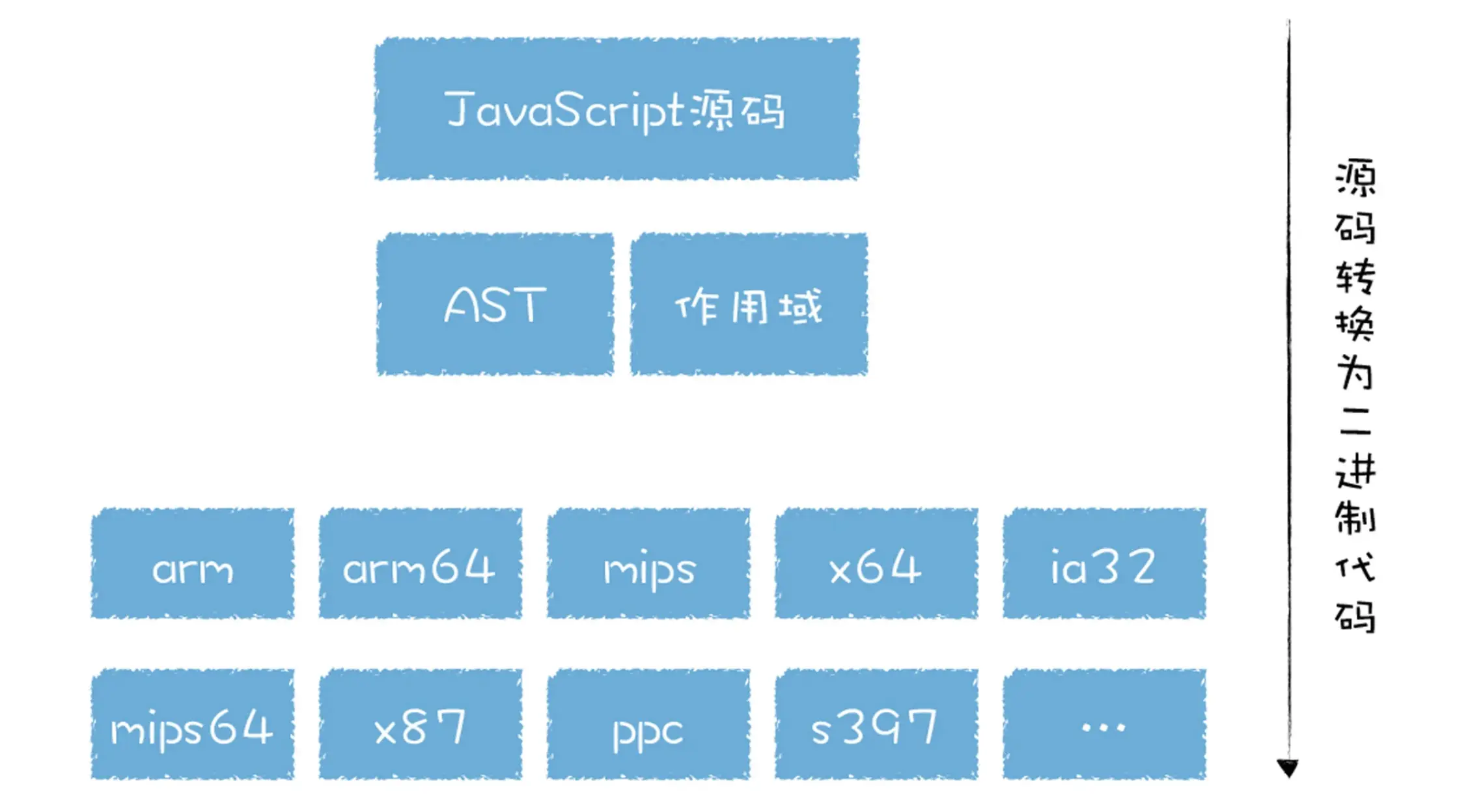
机器码在不同的 CPU 架构中是各不相同的。直接将抽象语法树(AST)转换为特定的机器码,意味着基线编译器和优化编译器需要为每种 CPU 编写大量适配代码。早期的 V8 引擎采用了直接编译成机器码的策略,并使用内存缓存和硬盘存储,这导致在不同设备和 CPU 上生成的机器码存在差异
所以 v8 采用先将AST转换成字节码,再将字节码转换成机器码,由于字节码(消除了平台的差异性)和 CPU 执行机器码过程类似,将字节码转换成机器码就会容易很多 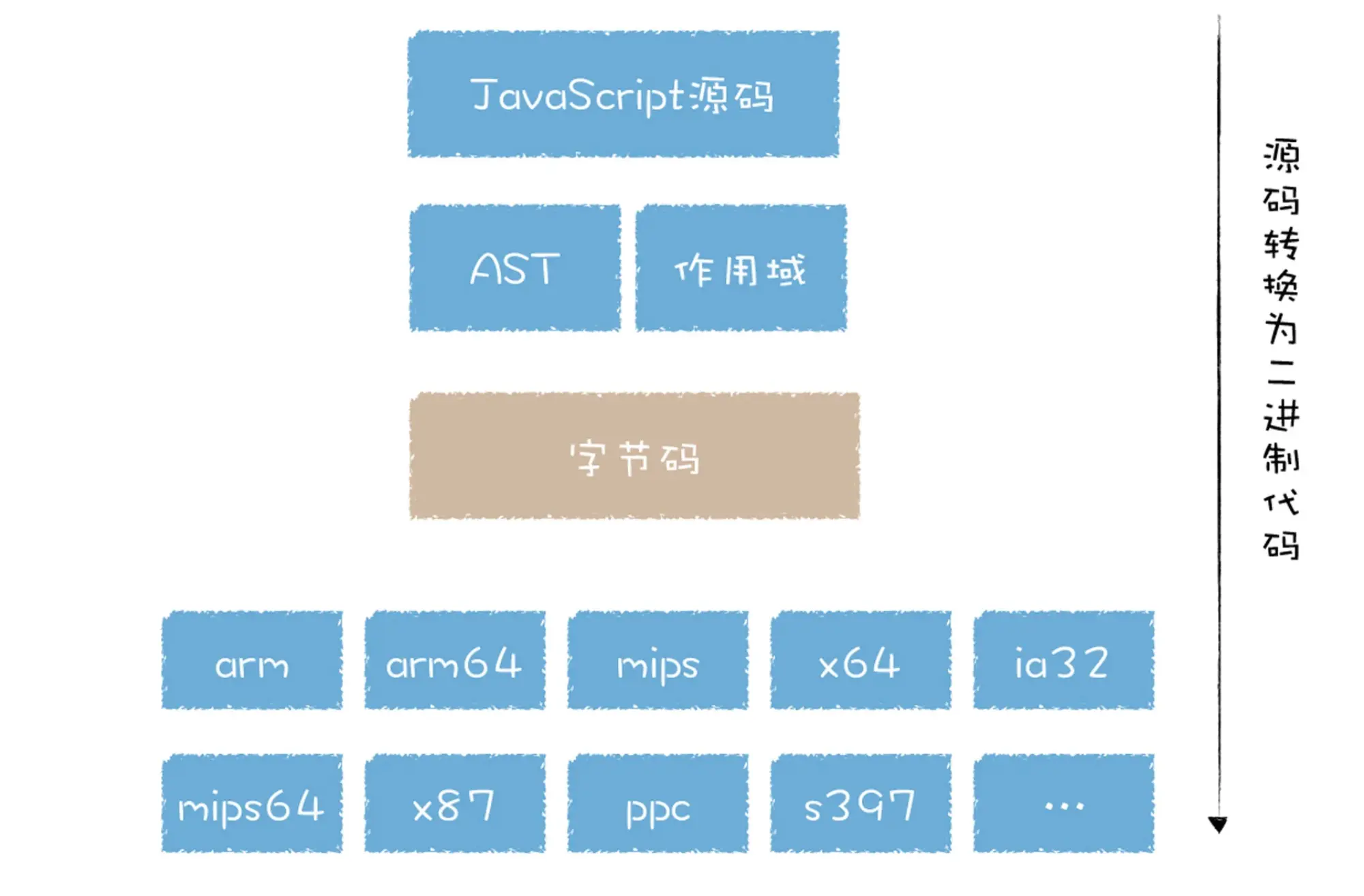
小结:
早期的 V8 为了提升代码的执行速度,直接将 JavaScript 源代码编译成了没有优化的二进制的机器代码,如果某一段二进制代码执行频率过高,那么 V8 会将其标记为热点代码,热点代码会被优化编译器优化,优化后的机器代码执行效率更高。
不过随着移动设备的普及,V8 团队逐渐发现将 JavaScript 源码直接编译成二进制代码存在两个致命的问题:
- 时间问题:编译时间过久,影响代码启动速度;
- 空间问题:缓存编译后的二进制代码占用更多的内存。
这两个问题无疑会阻碍 V8 在移动设备上的普及,于是 V8 团队大规模重构代码,引入了中间的字节码。字节码的优势有如下三点:
- 解决启动问题:生成字节码的时间很短;
- 解决空间问题:字节码占用内存不多,缓存字节码会大大降低内存的使用;
- 代码架构清晰:采用字节码,可以简化程序的复杂度,使得 V8 移植到不同的 CPU 架构平台更加容易。
字节码(二):解释器是如何解释执行字节码的?
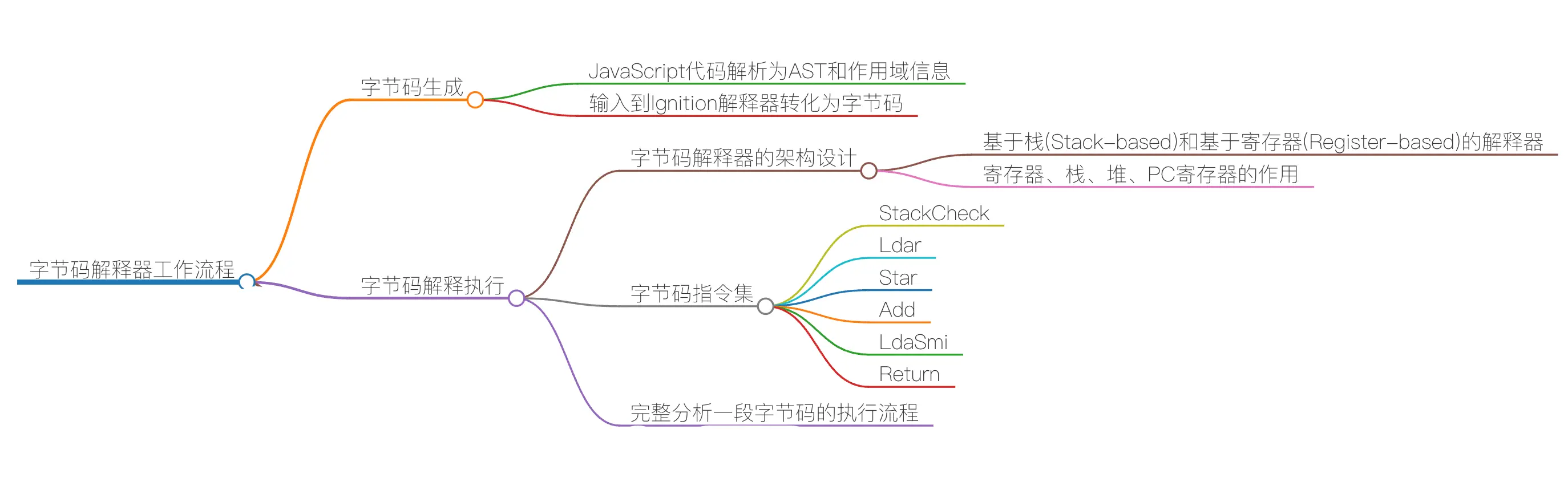
字节码的解释执行在编译流水线中的位置如下图: 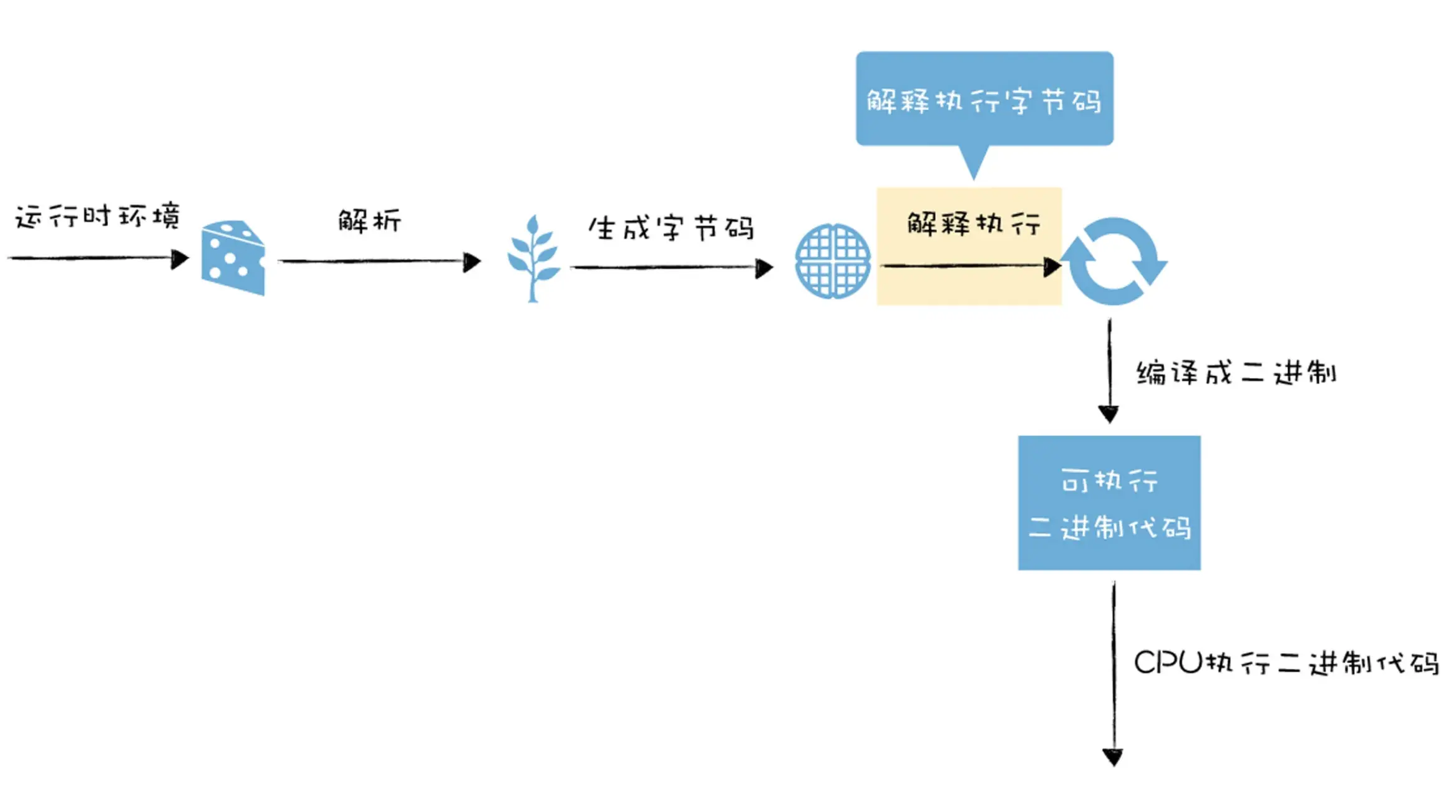
生成字节码
function add(x, y) {
var z = x + y;
return z;
}
console.log(add(1, 2));生成 AST
[generating bytecode for function: add]
--- AST ---
FUNC at 12
KIND 0
LITERAL ID 1
SUSPEND COUNT 0
NAME "add"
PARAMS
VAR (0x7fa7bf8048e8) (mode = VAR, assigned = false) "x"
VAR (0x7fa7bf804990) (mode = VAR, assigned = false) "y"
DECLS
VARIABLE (0x7fa7bf8048e8) (mode = VAR, assigned = false) "x"
VARIABLE (0x7fa7bf804990) (mode = VAR, assigned = false) "y"
VARIABLE (0x7fa7bf804a38) (mode = VAR, assigned = false) "z"
BLOCK NOCOMPLETIONS at -1
EXPRESSION STATEMENT at 31
INIT at 31
VAR PROXY local[0] (0x7fa7bf804a38) (mode = VAR, assigned = false) "z"
ADD at 32
VAR PROXY parameter[0] (0x7fa7bf8048e8) (mode = VAR, assigned = false) "x"
VAR PROXY parameter[1] (0x7fa7bf804990) (mode = VAR, assigned = false) "y"
RETURN at 37
VAR PROXY local[0] (0x7fa7bf804a38) (mode = VAR, assigned = false) "z"将 AST 图形化 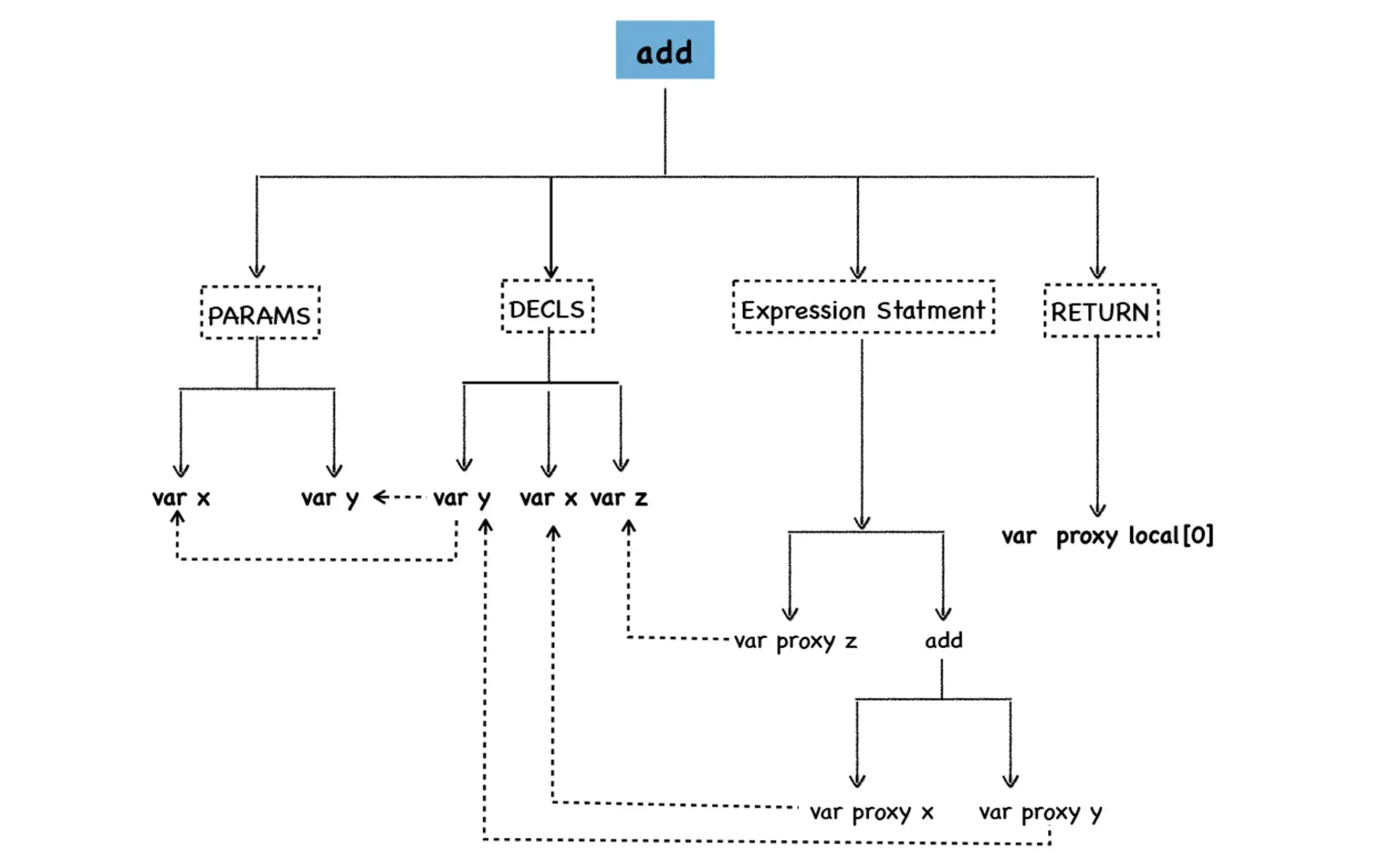
将函数拆成了 4 部分
- 参数声明(PARAMS):包括声明中的所有参数,这里是 x 和 y,也可以使用 arguments
- 变量声明节点(DECLS):出现了 3 个变量:x、y、z,你会发现 x 和 y 的地址和 PARAMS 中是相同的,说明他们是同一块数据
- 表达式节点:ADD 节点下有 VAR PROXY parameter[0] 和 VAR PROXY parameter[1]
- RETURN 节点:指向了 z 的值,这里是 local[0]
生成 AST 的同时,还生成了 add 函数的作用域
Global scope:
function add (x, y) { // (0x7f9ed7849468) (12, 47)
// will be compiled
// 1 stack slots
// local vars:
VAR y; // (0x7f9ed7849790) parameter[1], never assigned
VAR z; // (0x7f9ed7849838) local[0], never assigned
VAR x; // (0x7f9ed78496e8) parameter[0], never assigned
}在解析阶段,普通变量默认值是 undefined,函数声明指向实际的函数对象;执行阶段,变量会指向栈和堆相应的数据 如下图所示: 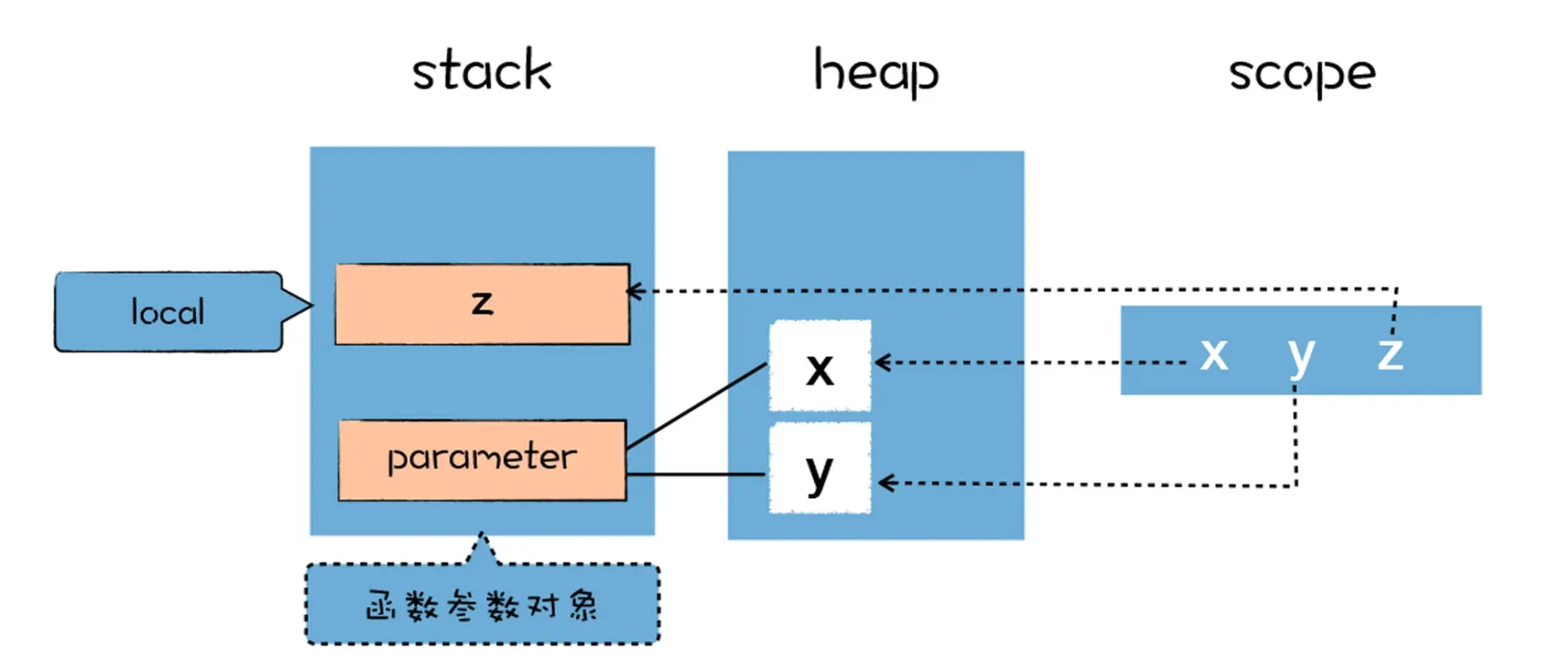
AST 作为输入传到自己字节码生成器中(BytecodeGenerator),它是 lgnition 的一部分,生成以函数为单位的字节码
[generated bytecode for function: add (0x079e0824fdc1 <SharedFunctionInfo add>)]
Parameter count 3
Register count 2
Frame size 16
0x79e0824ff7a @ 0 : a7 StackCheck
0x79e0824ff7b @ 1 : 25 02 Ldar a1
0x79e0824ff7d @ 3 : 34 03 00 Add a0, [0]
0x79e0824ff80 @ 6 : 26 fb Star r0
0x79e0824ff82 @ 8 : 0c 02 LdaSmi [2]
0x79e0824ff84 @ 10 : 26 fa Star r1
0x79e0824ff86 @ 12 : 25 fb Ldar r0
0x79e0824ff88 @ 14 : ab Return
Constant pool (size = 0)
Handler Table (size = 0)
Source Position Table (size = 0)这里 Parameter count 3 表示显示的参数 x 和 y ,及隐式参数 this
最终的字节码
StackCheck
Ldar a1
Add a0, [0]
Star r0
LdaSmi [2]
Star r1
Ldar r0
Return理解字节码:解释器的架构设计
有两种解释器:
基于栈(State-based)
在基于栈的解释器中,栈是一个实际的内存结构,数据(函数参数、中间运算结果、变量)存储在内存的栈区。
基于寄存器(Register-based)
支持寄存器的指令操作,使用寄存器保存参数、中间计算结果 在基于寄存器的解释器中,虽然也有栈的概念,但栈的功能可能会通过寄存器来模拟,栈的操作可能会通过寄存器的读写来实现。因此,基于寄存器的解释器中的“栈”更多是一个逻辑结构,而不是一个实际的内存栈。
基于栈的解释器:Java 虚拟机、.Net虚拟机,早期的V8 虚拟机;
优点:在处理函数调用、解决递归问题和切换上下文时简单快速
现在的 V8 采用了基于寄存器的设计
基于寄存器的虚拟机相比基于栈的虚拟机的优势:
更快的指令执行:
在基于栈的虚拟机中,每个指令的执行都需要频繁地访问内存栈,进行压栈和出栈操作。 而在基于寄存器的虚拟机中,指令的操作数都存储在寄存器中,可以直接进行计算和操作,无需访问内存。
举例来说,在计算 a + b 时:
基于栈的虚拟机需要先将 a 和 b 压入栈中,然后执行加法指令,最后将结果压入栈顶。这需要多次内存访问。
而基于寄存器的虚拟机可以直接将 a 和 b 加载到寄存器中,执行加法指令,结果也保留在寄存器中。这只需要一次寄存器访问,效率更高。
更高效的上下文切换:
基于栈的虚拟机中,当一个函数被调用时,它的参数、局部变量和返回地址等信息都会被存储在内存的栈区域中,形成一个栈帧。
举个例子,假设有一个函数 foo(a, b):
- 当 foo 函数被调用时:
首先会将函数参数 a 和 b 压入栈中。
然后会将返回地址压入栈中,以便函数执行完毕后能够返回到调用点。
接着会为函数的局部变量分配栈空间,并将它们的初始值压入栈中。
- 函数 foo 执行完毕后:
需要将函数的局部变量从栈中弹出。 然后弹出返回地址,以便能够跳转回调用点。 最后弹出函数参数,以便释放栈空间。 这整个过程就是保存和恢复栈帧的过程。在每次函数调用和返回时,虚拟机都需要进行这样的栈操作。
而在基于寄存器的虚拟机中,函数的参数、局部变量和返回地址都是存储在寄存器中,而不是内存栈上
因此,在进行上下文切换时,虚拟机只需要保存和恢复少量的寄存器状态,而不需要处理整个栈帧。这大大减少了上下文切换的开销,提高了切换效率。
更好的代码优化:
基于寄存器的架构为编译器提供了更多的优化空间。
编译器可以更容易地对基于寄存器的代码进行函数内联、循环展开、常量折叠等优化技术。
举例来说,在一个循环中,如果变量 i 被保存在寄存器中,编译器就可以直接对寄存器进行自增操作,而不需要频繁地从内存中加载和存储 i。这样可以大幅提高循环的执行效率。
总的来说,基于寄存器的虚拟机架构能够充分利用 CPU 的寄存器资源,减少内存访问开销,提高指令执行效率和上下文切换速度。同时,它也为编译器提供了更多的优化机会,进一步提升代码性能。这些优势使得基于寄存器的虚拟机在现代高性能计算系统中广受欢迎。
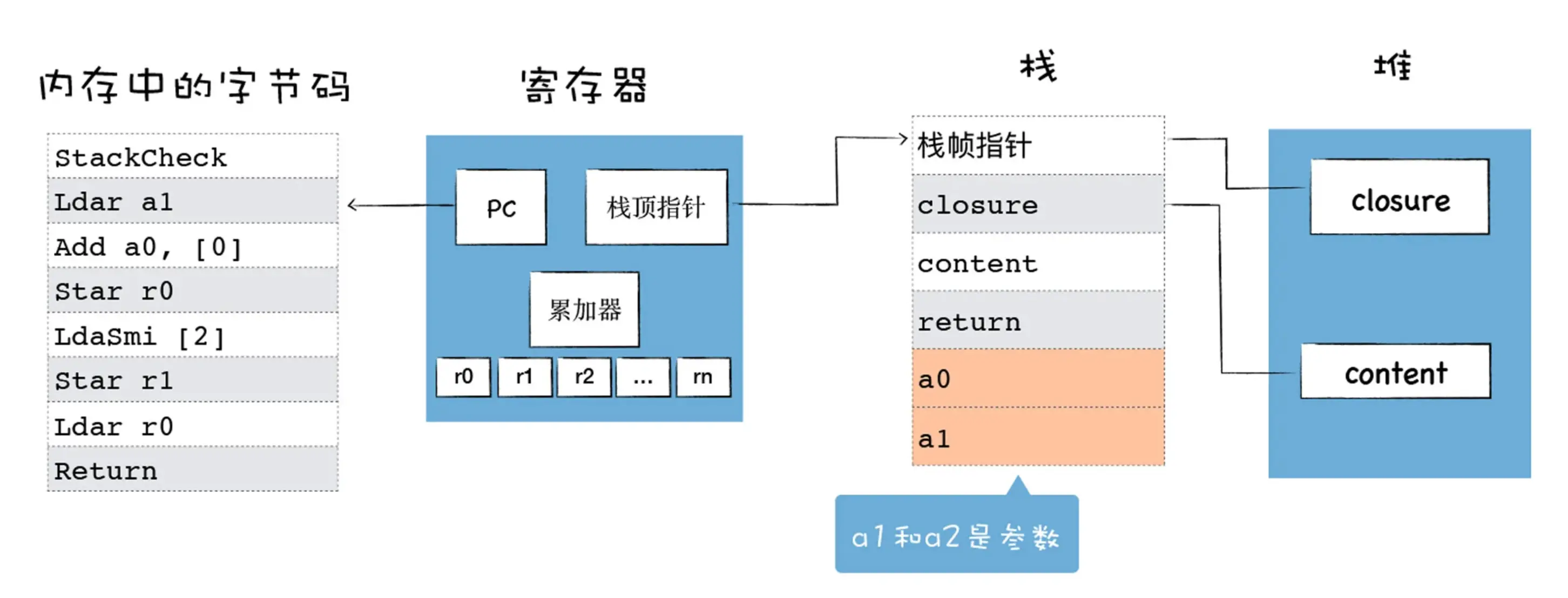
解释器执行时主要有四个模块,内存中的字节码、寄存器、栈、堆。
这和我们介绍过的 CPU 执行二进制机器代码的模式是类似的:
- 使用内存中的一块区域来存放字节码;
- 使用了通用寄存器 r0,r1,r2,…… 这些寄存器用来存放一些中间数据;
- PC 寄存器用来指向下一条要执行的字节码;
- 栈顶寄存器用来指向当前的栈顶的位置。
注意这里的累加器,它是一个非常特殊的寄存器,用来保存中间的结果,这体现在很多 V8 字节码的语义上面,我们来看下面这个字节码的指令:
Ldar a1Ldar 表示将寄存器中的值加载到累加器中,你可以把它理解为 LoaD Accumulator from Register ,就是把某个寄存器中的值,加载到累加器中。那么上面这个指令的意思就是把 a1 寄存器中的值,加载到累加器中,参看下图:
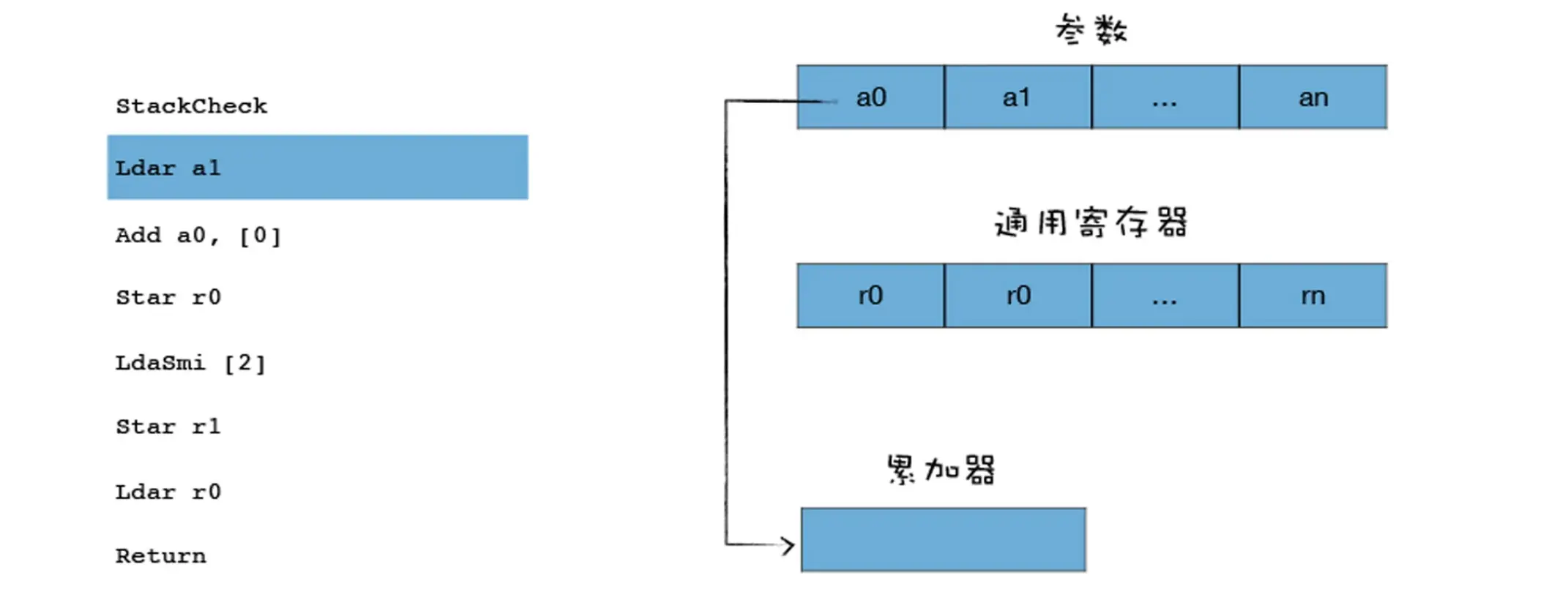
另外一个段字节码指令:
Star r0Star 表示 Store Accumulator Register, 你可以把它理解为 Store Accumulator to Register,就是把累加器中的值保存到某个寄存器中,上面这段代码的意思就是将累加器中的数值保存到 r0 寄存器中,具体流程你可以参看下图: 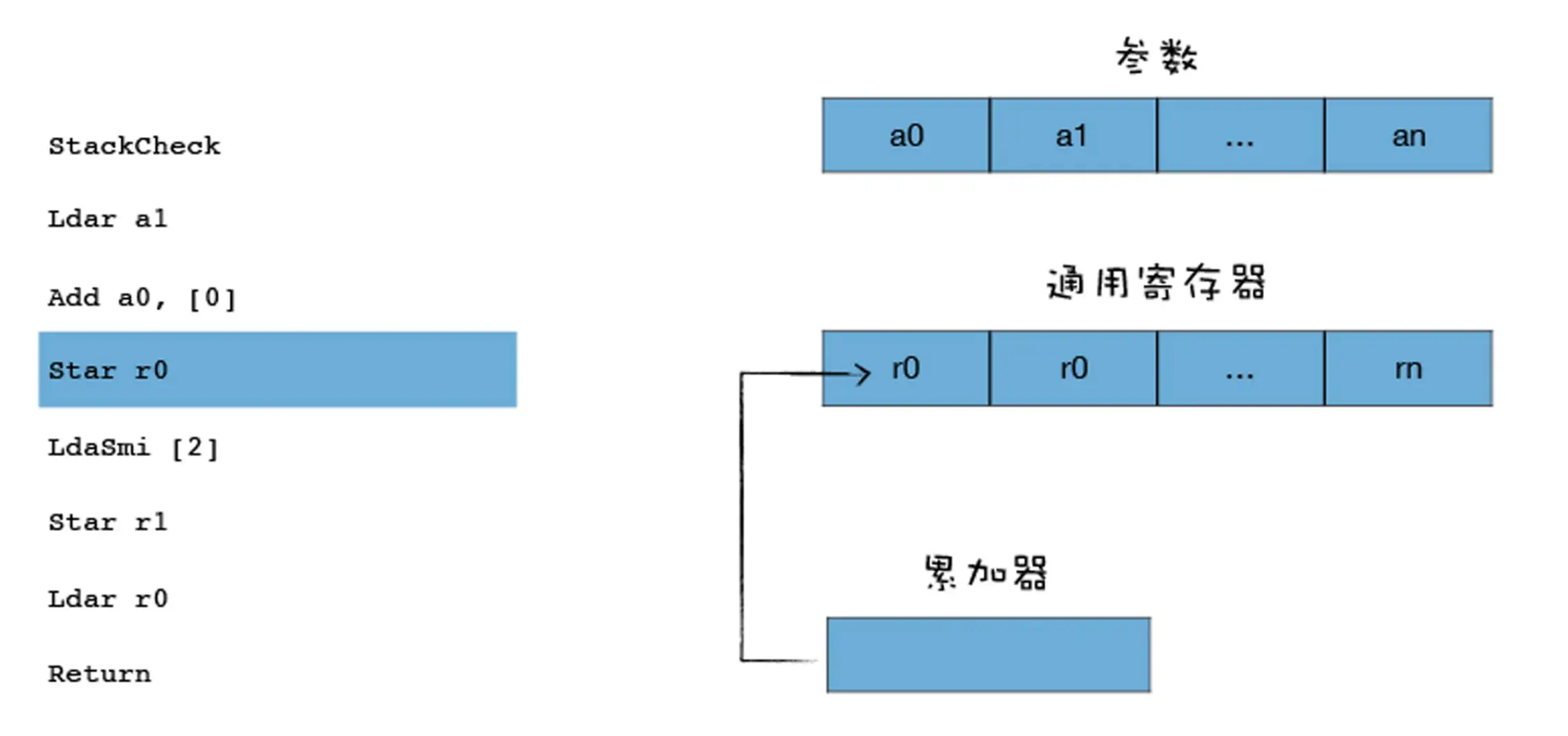
Add a0, [0]Add a0, [0]是从 a0 寄存器加载值并将其与累加器中的值相加,然后将结果再次放入累加器,最终操作如下图所示:
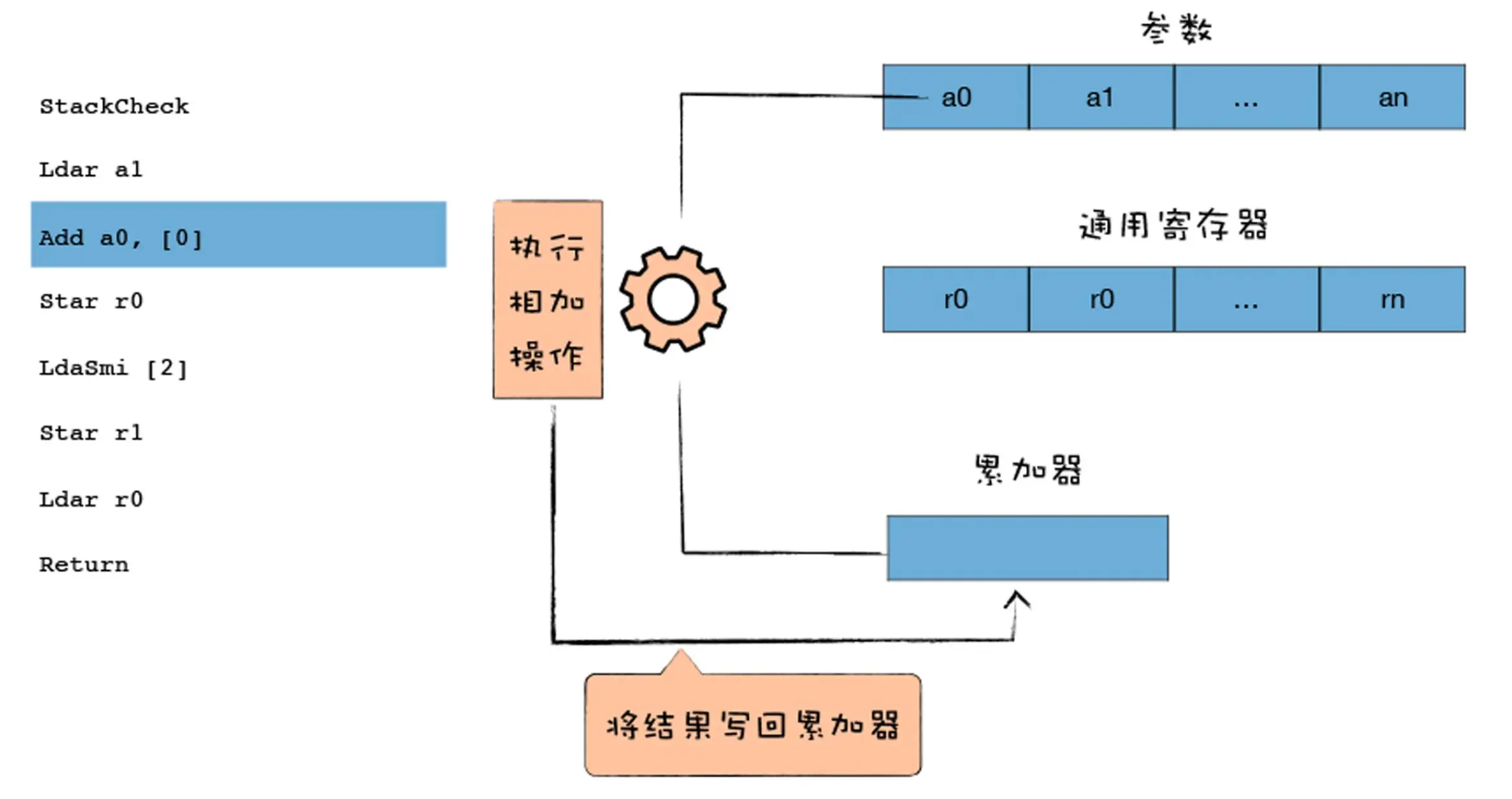
add a0 后面还跟了一个[0],这个符号是做什么的呢?
这个称之为 feedback vector slot,中文我们可以称为反馈向量槽,它是一个数组,解释器将解释执行过程中的一些数据类型的分析信息都保存在这个反馈向量槽中了,目的是为了给 TurboFan 优化编译器提供优化信息,很多字节码都会为反馈向量槽提供运行时信息
LdaSmi [2]这是将小整数(Smi)2 加载到累加器寄存器中,操作流程如下图:

ReturnReturn 结束当前函数的执行,并将控制权传回给调用方。返回的值是累加器中的值。
小结:
Ladr a1 指令:将 a1 寄存器中的值加载到累加器中
Star r0 指令:把累加器中的值保存到 r0 寄存器中
Add a0, [0] 指令:
- 从 a0 寄存器加载值并与累加器中的值相加,再将结果放入累加器中
- [0]:成为反馈向量槽(feedback vector slot),
目的是了给优化编译器(TurboFan)提供优化信息,它是一个数组,解释器将解释执行过程中的一些数据类型的分析信息保存在反馈向量槽中
LadSmi [2] 指令:将小整数(Smi)2 加载到累加器中 Return 指令:结束当前函数的执行,并将控制权还给调用方,返回的值是累加器中的值 StackCheck 指令:检查是栈是否到达溢出的上限
完整分析一段字节码
StackCheck
Ldar a1
Add a0, [0]
Star r0
LdaSmi [2]
Star r1
Ldar r0
Return执行这段代码时,整体的状态如下图所示: 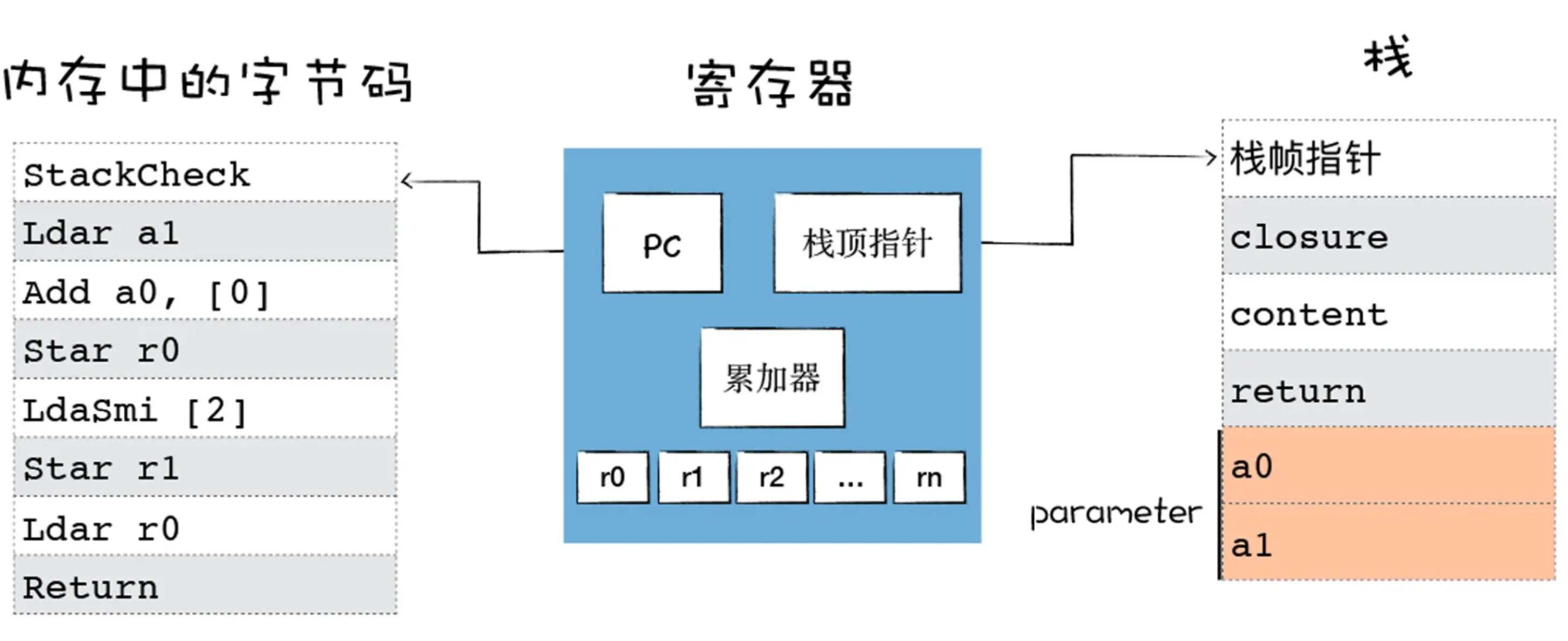
- 参数对象 parameter 保存在栈中,包含了 a0 和 a1 两个值,假设这两个值分别是 1 和 2;
- PC 寄存器指向了第一个字节码 StackCheck,我们知道,V8 在执行一个函数之前,会判断栈是否会溢出,这里的 StackCheck 字节码指令就是检查栈是否达到了溢出的上限,如果栈增长超过某个阈值,我们将中止该函数的执行并抛出一个 RangeError,表示栈已溢出。
然后继续执行下一条字节码,Ldar a1,这是将 a1 寄存器中的参数值加载到累加器中,这时候第一个参数就保存到累加器中了。
接下来执行加法操作,Add a0, [0],因为 a0 是第一个寄存器,存放了第一个参数,Add a0 就是将第一个寄存器中的值和累加器中的值相加,也就是将累加器中的 2 和通用寄存器中 a0 中的 1 进行相加,同时将相加后的结果 3 保存到累加器中。
现在累加器中就保存了相加后的结果,然后执行第四段字节码,Star r0,这是将累加器中的值,也就是 1+2 的结果 3 保存到寄存器 r0 中,那么现在寄存器 r0 中的值就是 3 了。
然后将常数 2 加载到累加器中,又将累加器中的 2 加载到寄存器 r1 中,我们发现这里两段代码可能没实际的用途,不过 V8 生成的字节码就是这样。
接下来 V8 将寄存器 r0 中的值加载到累加器中,然后执行最后一句 Return 指令,Return 指令会中断当前函数的执行,并将累加器中的值作为返回值。
这样 V8 就执行完成了 add 函数。
结论:
先分析了 V8 是如何生成字节码的,有了字节码,V8 的解释器就可以解释执行字节码了。通常有两种架构的解释器,基于栈的和基于寄存器的。基于栈的解释器会将一些中间数据存放到栈中,而基于寄存器的解释器会将一些中间数据存放到寄存器中。由于采用了不同的模式,所以字节码的指令形式是不同的。而目前版本的 V8 是基于寄存器的,所以又分析了基于寄存器的解释器的架构,这些寄存器和 CPU 中的寄存器类似,不过这里有一个特别的寄存器,那就是累加器。在操作过程中,一些中间结果都默认放到累加器中,比如 Ldar a1 就是将第二个参数加载到累加器中,Star r0 是将累加器中的值写入到 r0 寄存器中,Return 就是返回累加器中的数值。理解了累加器的重要性,我们又分析了一些常用字节码指令,这包括了 Ldar、Star、Add、LdaSmi、Return,了解了这些指令是怎么工作的之后,就可以完整地分析一段字节码的工作流程了。