编译流水线--- V8 对象结构与优化
V8 引擎中对象的内部结构:隐藏类、Properties 和 Elements"
在 V8 中,对象主要由三个指针构成,分别是隐藏类(Hidden Class),Property 还有 Element。
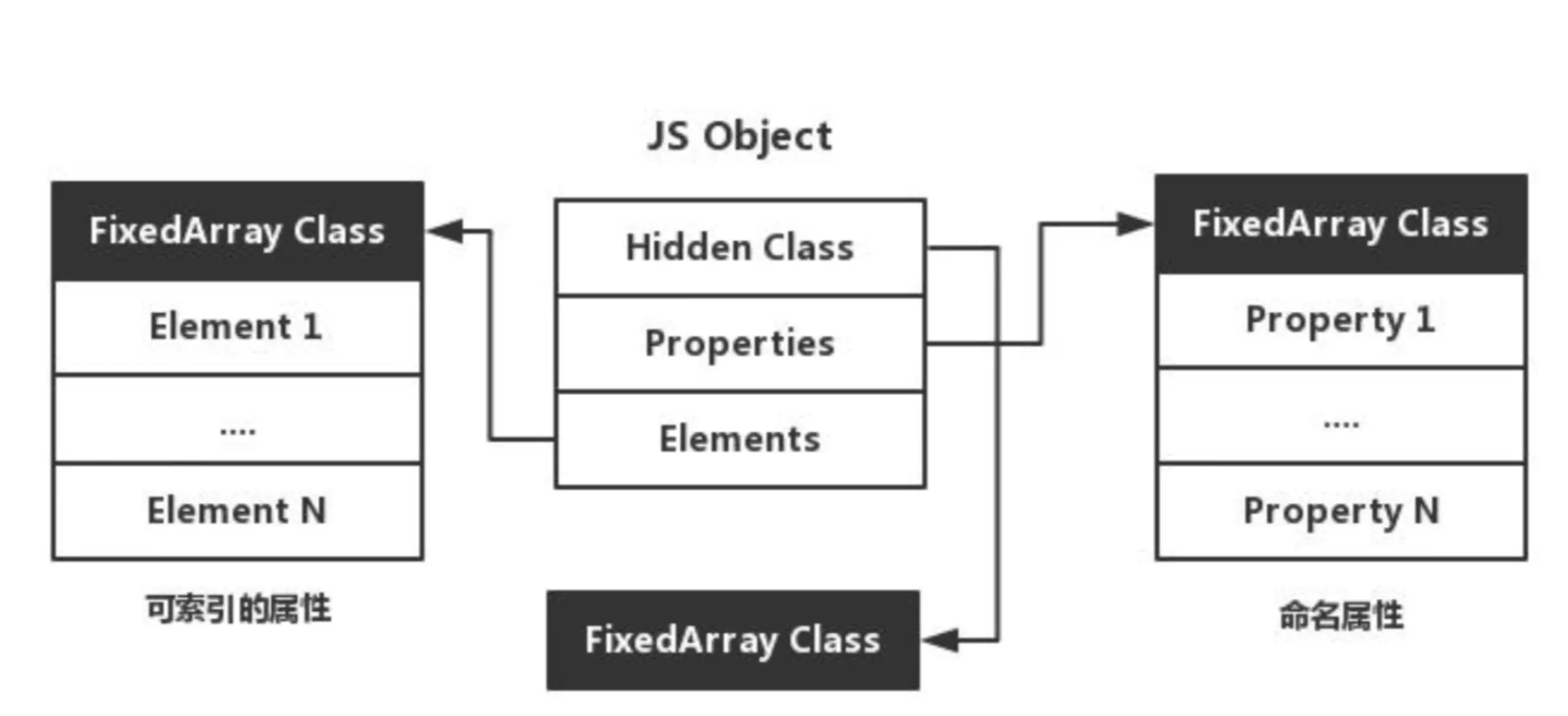
其中,隐藏类用于描述对象的结构。 Property 、Element 用于存放对象的属性,它们的区别主要体现在键名能否被索引。
Property 与 Element
// 可索引属性会被存储到 Elements 指针指向的区域
{ 1: "a", 2: "b" }
// 命名属性会被存储到 Properties 指针指向的区域
{ "first": 1, "second": 2 }var a = { 1: "a", 2: "b", "first": 1, 3: "c", "second": 2 }
var b = { "second": 2, 1: "a", 3: "c", 2: "b", "first": 1 }
console.log(a)
// { 1: "a", 2: "b", 3: "c", first: 1, second: 2 }
console.log(b)
// { 1: "a", 2: "b", 3: "c", second: 2, first: 1 }a 和 b 的区别在于 a 以一个可索引属性开头,b 以一个命名属性开头。在 a 中,可索引属性升序排列,命名属性先有 first 后有 second。在 b 中,可索引属性乱序排列,命名属性先有 second 后有first。
可以看到
- 索引的属性按照索引值大小升序排列,而命名属性根据创建的顺序升序排列。
- 在同时使用可索引属性和命名属性的情况下,控制台打印的结果中,两种不同属性之间存在的明显分隔。
- 无论是可索引属性还是命名属性先声明,在控制台中总是以相同的顺序出现(在我的浏览器中,可索引属性总是先出现)。
这两点都可以从侧面印证这两种属性是分开存储的。
我们看看两种属性的快照:
function Foo1() {}
var a = new Foo1();
var b = new Foo1();
a.name = 'aaa';
a.text = 'aaa';
b.name = 'bbb';
b.text = 'bbb';
a[1] = 'aaa';
a[2] = 'aaa';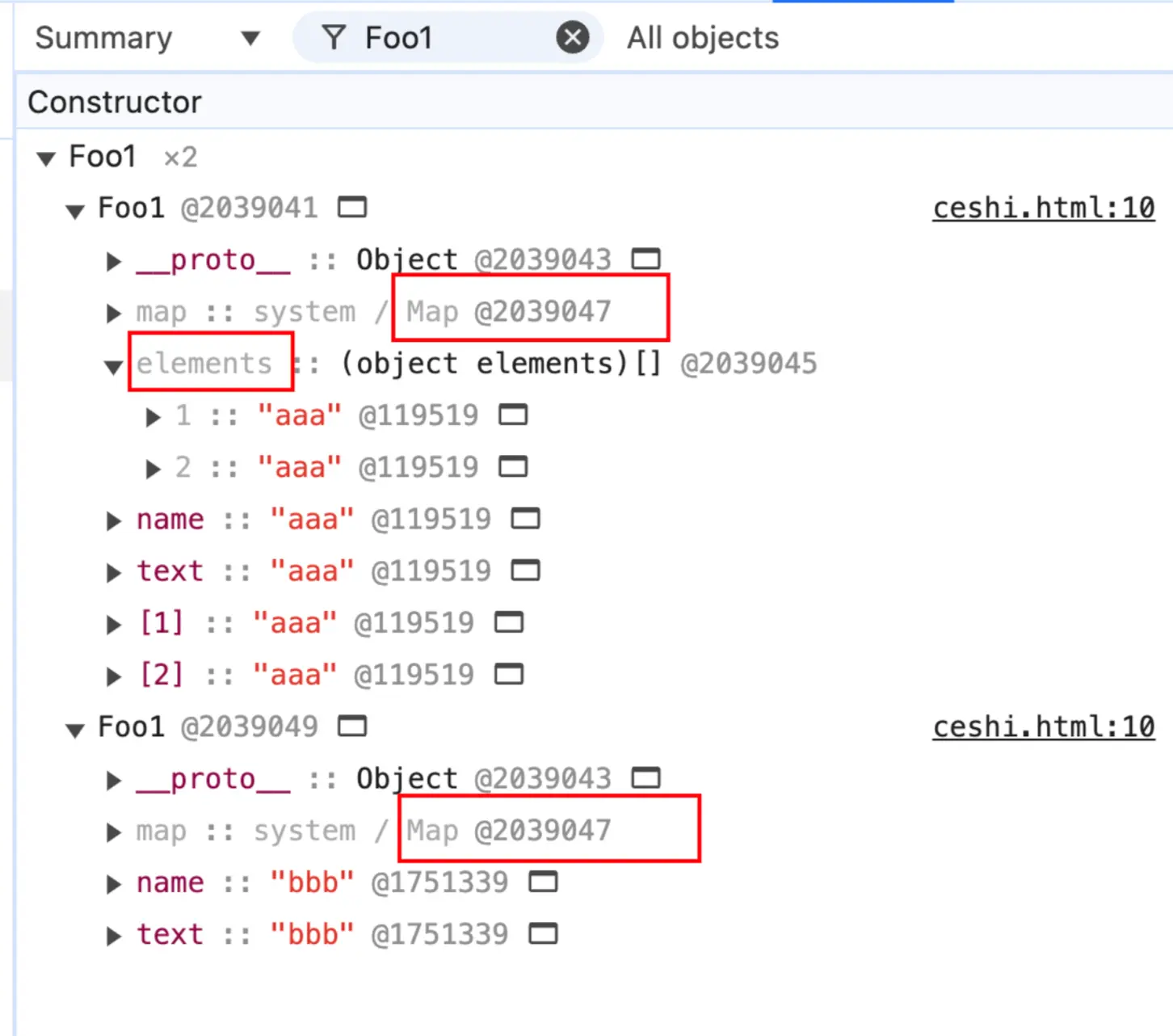 a、b 都有命名属性 name 和 text,此外 a 还额外多了两个可索引属性。从快照中可以明显的看到,可索引属性是存放在 Elements 中的,此外,a 和 b 具有相同的结构(这个结构会在下文中介绍)。 你可能会有点好奇,这两个对象的属性不一样,怎么会有相同的结构呢?要理解这个问题,首先可以问自己三个问题。
a、b 都有命名属性 name 和 text,此外 a 还额外多了两个可索引属性。从快照中可以明显的看到,可索引属性是存放在 Elements 中的,此外,a 和 b 具有相同的结构(这个结构会在下文中介绍)。 你可能会有点好奇,这两个对象的属性不一样,怎么会有相同的结构呢?要理解这个问题,首先可以问自己三个问题。 - 为什么要把对象存起来?当然是为了之后要用呀。
- 要用的时候需要做什么?找到这个属性咯。
- 描述结构是为了做什么呢?按图索骥,方便查找呀。
那么,对于可索引属性来说,它本身已经是有序地进行排列了,我们为什么还要多次一举通过它的结构去查找呢。既然不用通过它的结构查找,那么我们也不需要再去描述它的结构了是吧。这样,应该就不难理解为什么 a 和 b 具有相同的结构了,因为它们的结构中只描述了它们都具有 name 和 text 这样的情况。
当然,这也是有例外的。我们在上面的代码中再加入一行。 a[1111] = 'aaa';
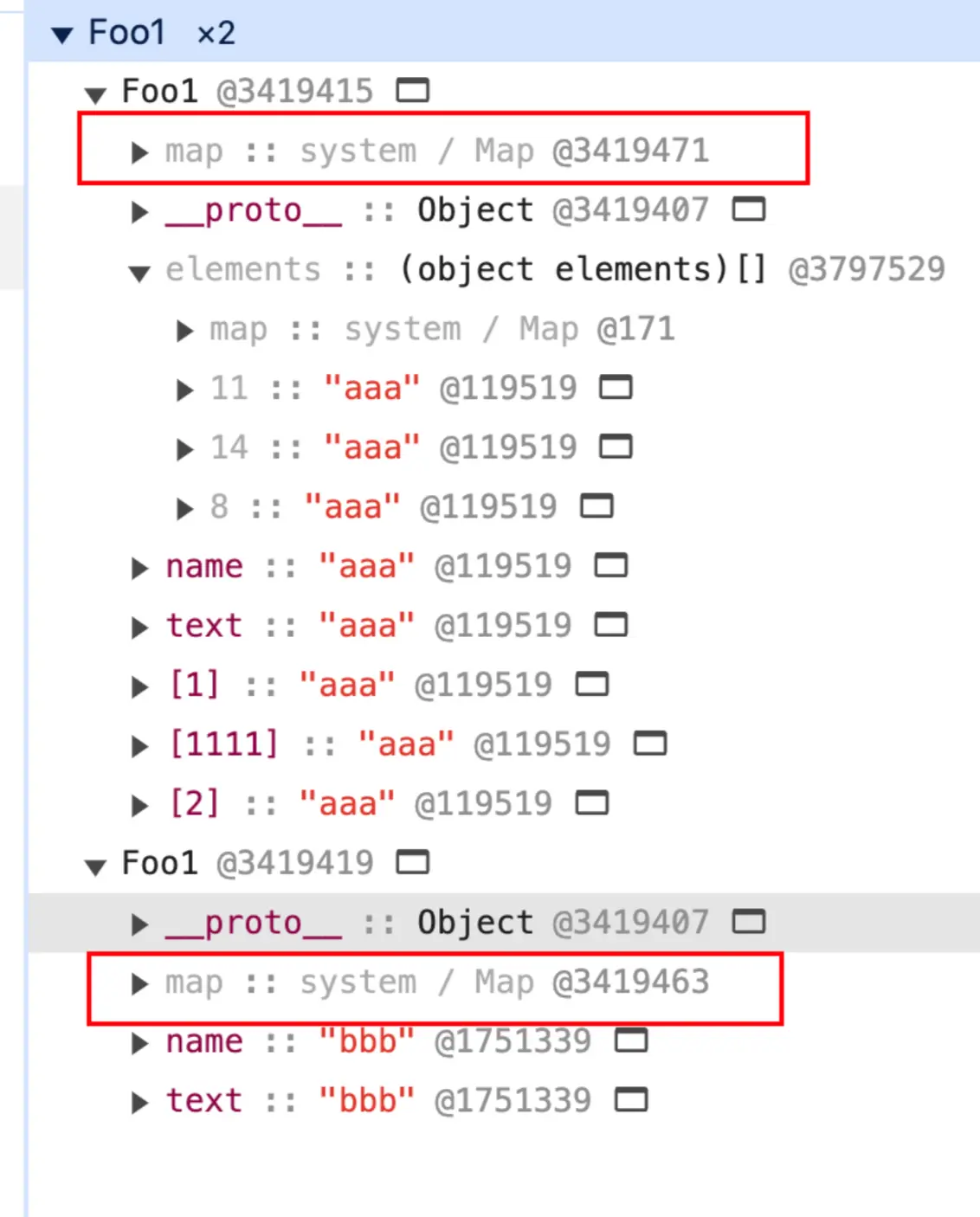
可以看到,此时隐藏类发生了变化,Element 中的数据存放也变得没有规律了。这是因为,当我们添加了 a[1111] 之后,数组会变成稀疏数组。为了节省空间,稀疏数组会转换为哈希存储的方式,而不再是用一个完整的数组描述这块空间的存储。所以,这几个可索引属性也不能再直接通过它的索引值计算得出内存的偏移量。至于隐藏类发生变化,可能是为了描述 Element 的结构发生改变(这个图片可以与下文中慢属性的配图进行比较,可以看到 Foo1 的 Property 并没有退化为哈希存储,只是 Element 退化为哈希存储导致隐藏类发生改变)
命名属性的不同存储方式:
V8 中命名属性有三种的不同存储方式:对象内属性(in-object)、快属性(fast)和慢属性(slow)。
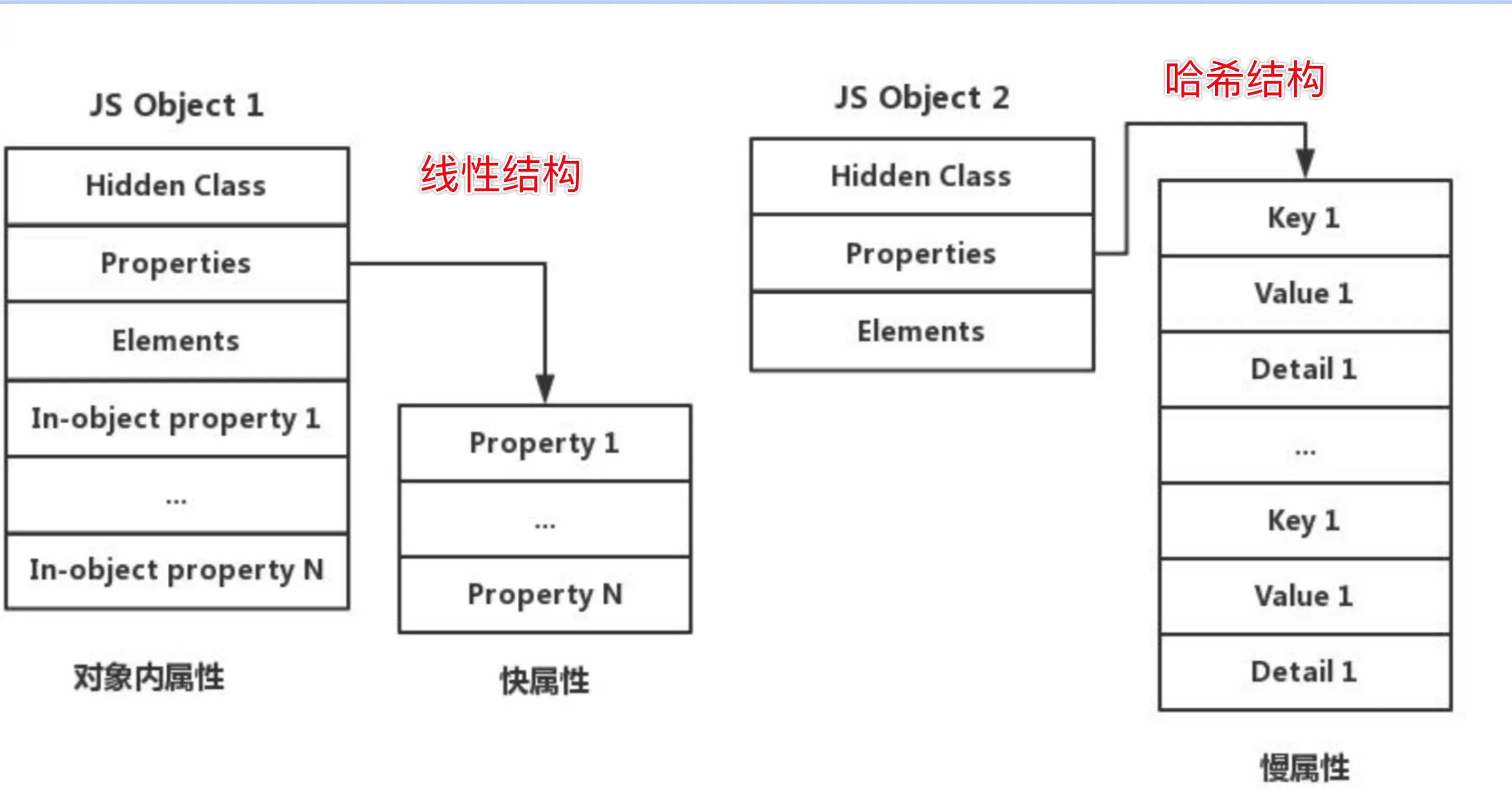
- 对象内属性(In-object properties):
- 这种属性是直接存储在对象本身内部的,提供了最快的访问速度。
- 快属性(Fast properties):
- 这种属性虽然不存储在对象内部,但是通过隐藏类可以快速定位到它的位置,访问速度也很快。
- 慢属性(Slow properties):
- 这种属性的存储方式与前两种不同,它会将属性的完整结构存储在一个单独的数据结构中,通常是一个哈希表。
- 访问慢属性需要先查找这个哈希表,所以速度相对较慢。
通过一个例子来说明。
// 实验2 三种不同类型的 Property 存储模式
function Foo2() {}
var a = new Foo2();
var b = new Foo2();
var c = new Foo2();
for (var i = 0; i < 10; i++) {
a[new Array(i + 2).join('a')] = 'aaa';
}
for (var i = 0; i < 12; i++) {
b[new Array(i + 2).join('b')] = 'bbb';
}
for (var i = 0; i < 30; i++) {
c[new Array(i + 2).join('c')] = 'ccc';
}对象内属性和快属性
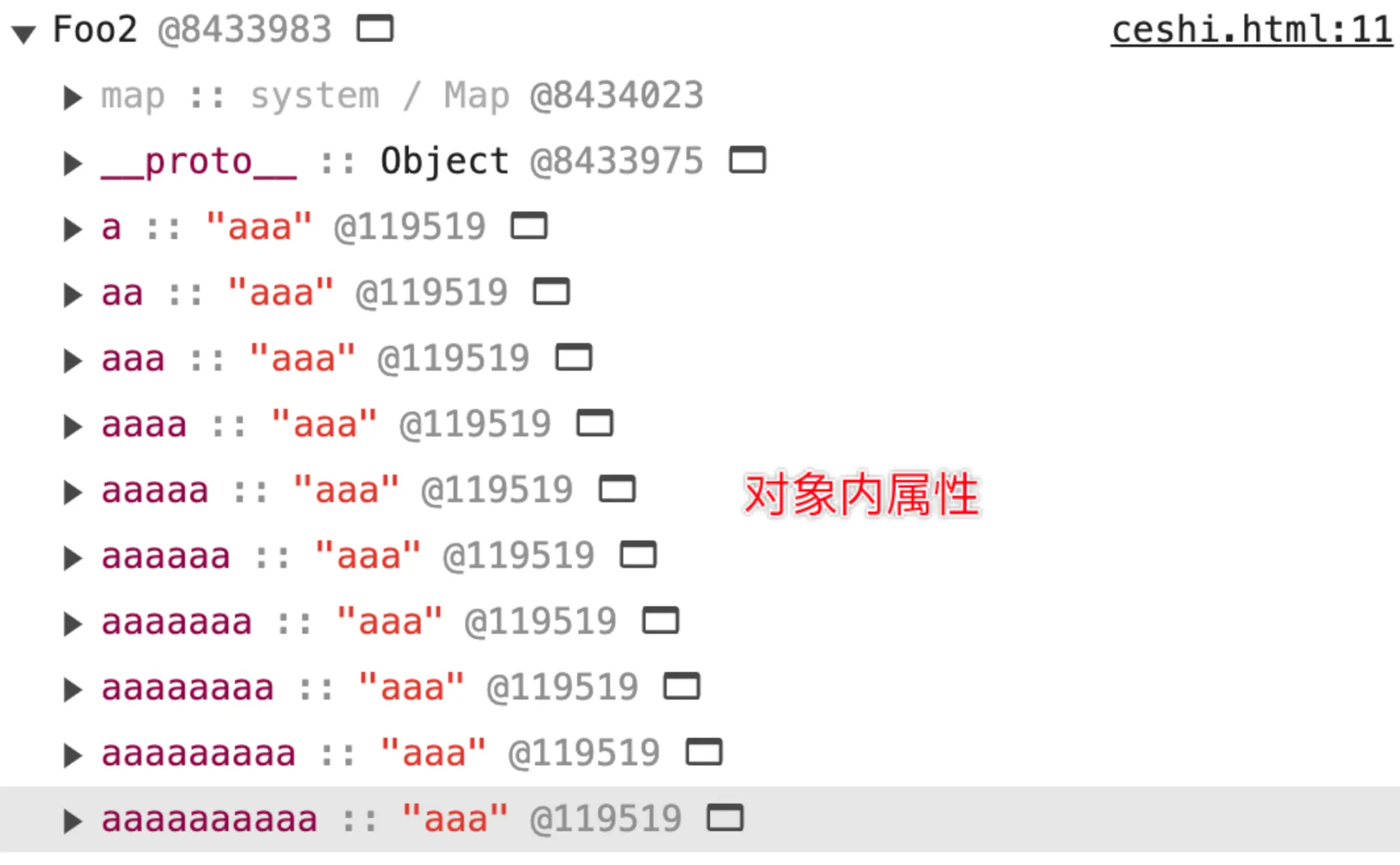
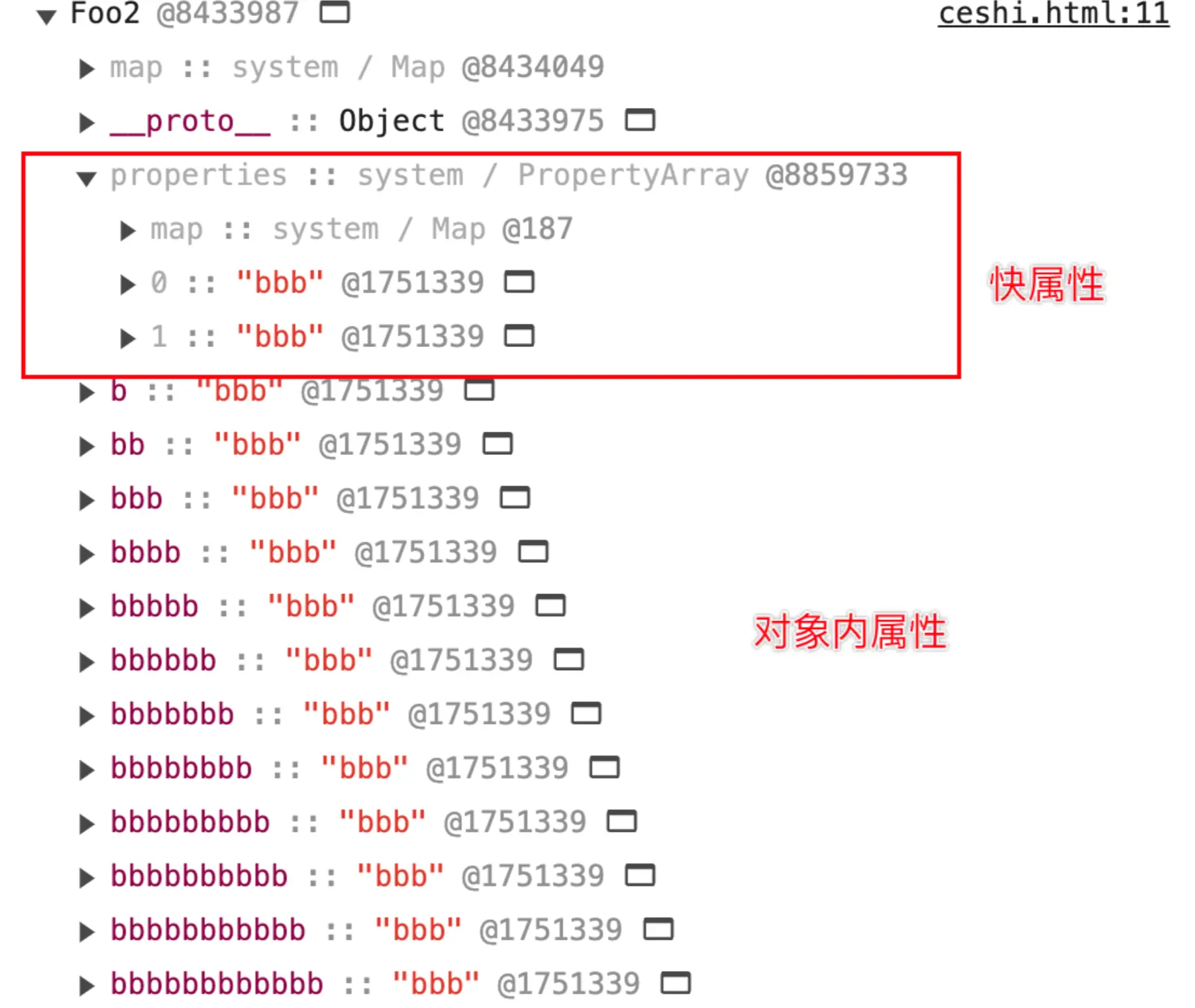
从某种程度上讲,对象内属性和快属性实际上是一致的。只不过,对象内属性是在对象创建时就固定分配的,空间有限。在我的实验条件下,对象内属性的数量固定为十个,且这十个空间大小相同(可以理解为十个指针)。当对象内属性放满之后,会以快属性的方式,在 properties 下按创建顺序存放。相较于对象内属性,快属性需要额外多一次 properties 的寻址时间,之后便是与对象内属性一致的线性查找。
慢属性
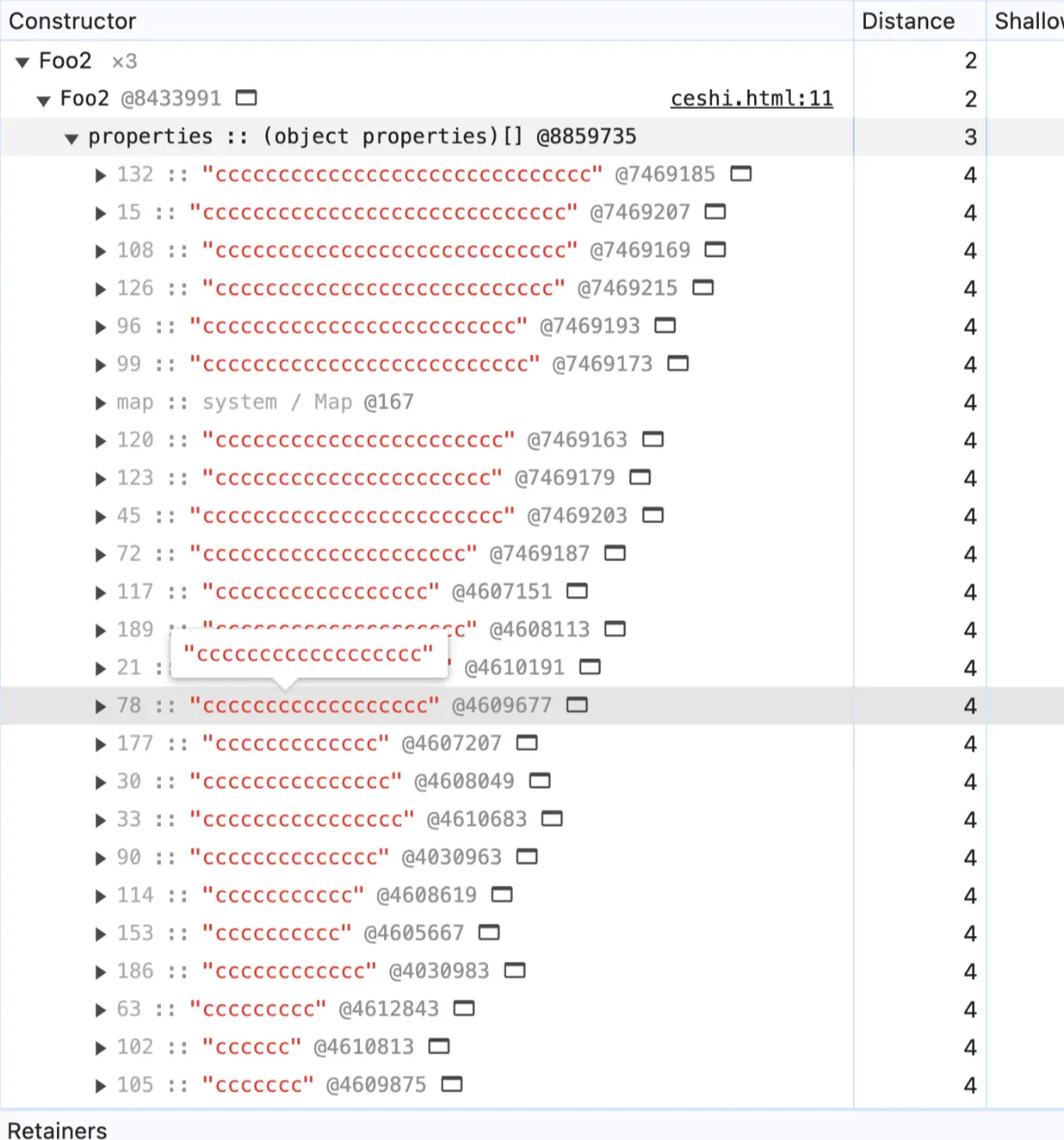 接着我们来看看 c。这个实在是太长了,只截取了一部分。可以看到,和 b (快属性)相比,properties中的索引变成了毫无规律的数,意味着这个对象已经变成了哈希存取结构了。
接着我们来看看 c。这个实在是太长了,只截取了一部分。可以看到,和 b (快属性)相比,properties中的索引变成了毫无规律的数,意味着这个对象已经变成了哈希存取结构了。 
对象内属性和快属性做的事情很简单,线性查找每一个位置是不是指定的位置,这部分的耗时可以理解为至多 N 次简单位运算(N 为属性的总数)的耗时,时间复杂度 O(N), 而慢属性需要先经过哈希算法计算。这是一个复杂运算,时间上若干倍于简单位运算。另外,哈希表是个二维空间,所以通过哈希算法计算出其中一维的坐标后,在另一维上仍需要线性查找。所以,当属性非常少的时候为什么不用慢属性即不用哈希表。
那为什么不一直用对象内属性或快属性呢?
这是因为属性太多的时候,这两种方式可能就没有慢属性快了。假设哈希运算的代价为 60 次简单位运算,哈希算法的表现良好。如果只用对象内属性或快属性的方式存,当我需要访问第 120 个属性,就需要 120 次简单位运算。而使用慢属性,我们需要一次哈希计算(60 次简单位运算)+ 第二维的线性比较(远小于 60 次,已假设哈希算法表现良好,那属性在哈希表中是均匀分布的)。
隐藏类
隐藏类:如何在内存中快速查找对象属性?
- 为了提升对象属性访问速度,引入隐藏类
- 为了加速运算引入内联缓存
为什么静态语言效率高
JavaScript 在运行时,对象的属性可以被修改,所以 V8在解析对象时,比如:解析 start.x 时,它不知道 start 中是否有 x ,也不知道 x 相对于 start 的偏移量是多少,简单说 V8 不知道 start 对象的具体行状
所以当 JavaScript 查询 start.x 时,过程非常慢
静态语言,比如 C++ 在声明对象之前需要定义该对象的结构(行状),执行之前会被编译,编译的时候,行状是固定的,也就是说在执行过程中,对象的形状是无法改变的
所以当C++查询 start.x 使,编译器在编译的时候,会直接将 x 相对于 start 对象的地址写进汇编指令中,查询时直接读取 x 的地址,没有查找环节
V8 为了做到这点,做了两个假设:
- 对象创建好了之后不会添加新的属性
- 对象创建好了之后也不会删除属性
然后 V8 为每个对象创建一个隐藏类,记录基础的信息
- 对象中所包含的所有属性
- 每个属性相对于对象的偏移量。
在 V8 中隐藏类有称为 map,即每个对象都有一个 map 属性,指向内存中的隐藏类
有了 map 之后,当访问 start.x 时,V8 会先去 start.map 中查询 x 相对 start 的偏移量,然后将 start 对象的地址加上偏移量就得到了 x 属性的值在内存中的地址了
作为一个基于寄存器架构的虚拟机, V8 为什么会将对象和对象的隐藏类存储在内存中,而不是完全存储在寄存器中?
寄存器资源有限:寄存器是一种有限的资源,无法容纳所有的对象属性信息。将属性信息存储在内存中的隐藏类中,可以更好地利用内存资源。对于简单的基本类型变量(如数字、布尔值等),V8 会将它们直接存储在寄存器中。这是最高效的存储方式。
对象属性的动态性:对象的属性可能会动态添加或删除,这种动态性很难在寄存器中高效地表示和管理。而将属性信息存储在隐藏类中,可以更好地应对对象属性的动态变化。 所以 V8 会将对象的属性信息(如属性名、属性值等)则会存储在内存中的隐藏类(map)中,而不是直接存储在寄存器中,而寄存器只是存储对象的内存地址
优化访问性能:通过将对象指针存储在寄存器中,再根据隐藏类中的信息访问属性,可以在保持寄存器访问速度的同时,也能够对对象属性进行更多的优化。
当访问对象的属性时,V8 会先从寄存器中读取对象的指针(对象的内存地址),根据这个对象指针在内存中找到对应的对象,然后读该对象的隐藏类(map)。隐藏类记录了这个对象的所有属性信息。根据隐藏类中记录的属性信息,计算出要访问的属性在内存中的具体位置。最后,根据计算出的位置,从内存中读取出属性的值。
如果两个对象行状相同,V8 会为其复用同一个隐藏类:
- 减少隐藏类的创建次数,也间接加速了代码的执行速度
- 减少了隐藏类的存储空间
两个对象的形状相同,要满足:
- 相同的属性名称
- 相同的属性顺序
- 相同的属性类型
- 相等的属性个数
如果动态改变了对象的行状,V8 就会重新构建新的隐藏类
delete 操作的影响
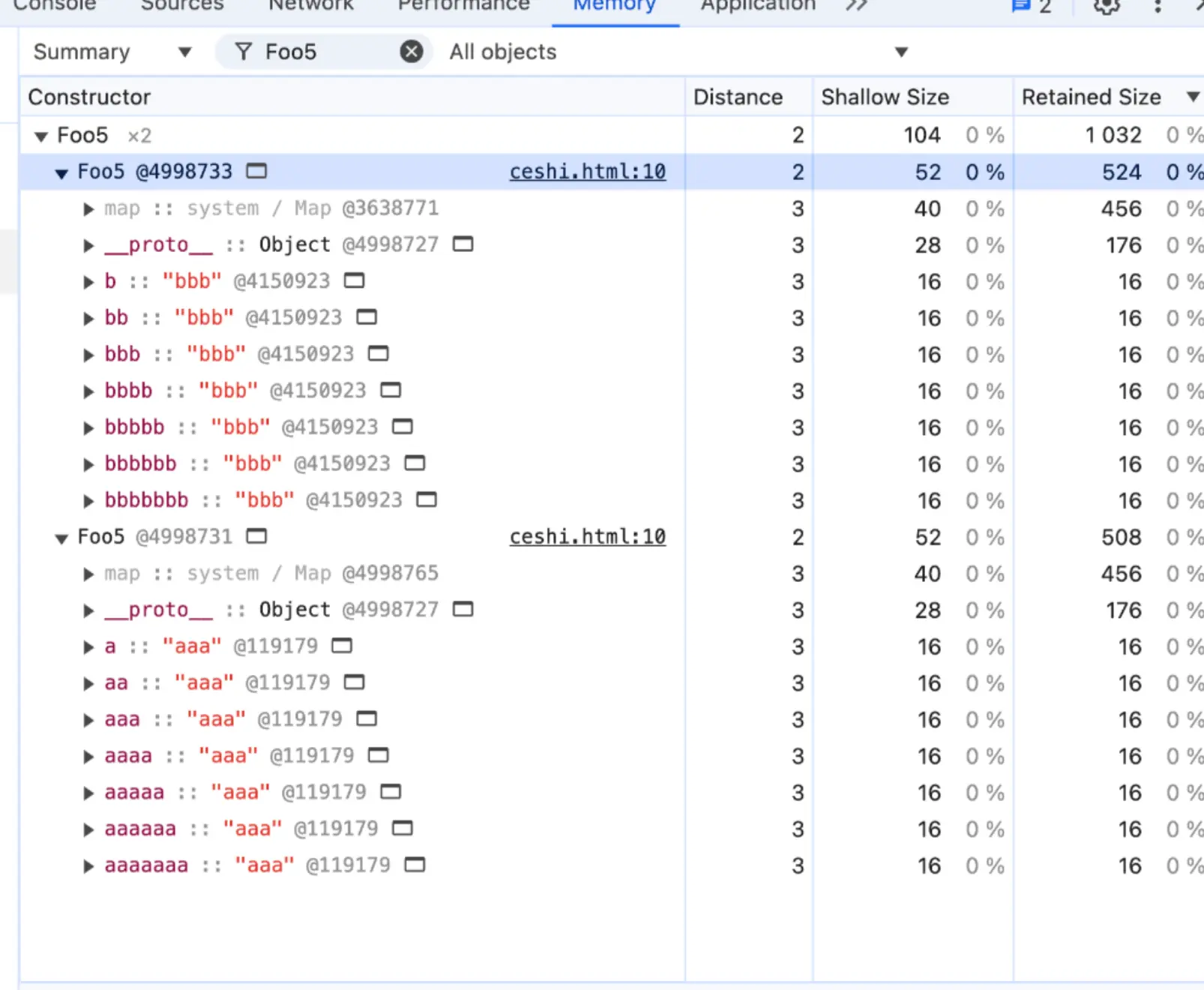
function Foo5() {}
var a = new Foo5();
var b = new Foo5();
for (var i = 1; i < 8; i++) {
a[new Array(i + 1).join('a')] = 'aaa';
b[new Array(i + 1).join('b')] = 'bbb';
}
function Foo5() {}
var a = new Foo5();
var b = new Foo5();
for (var i = 1; i < 8; i++) {
a[new Array(i + 1).join('a')] = 'aaa';
b[new Array(i + 1).join('b')] = 'bbb';
}
delete a.a;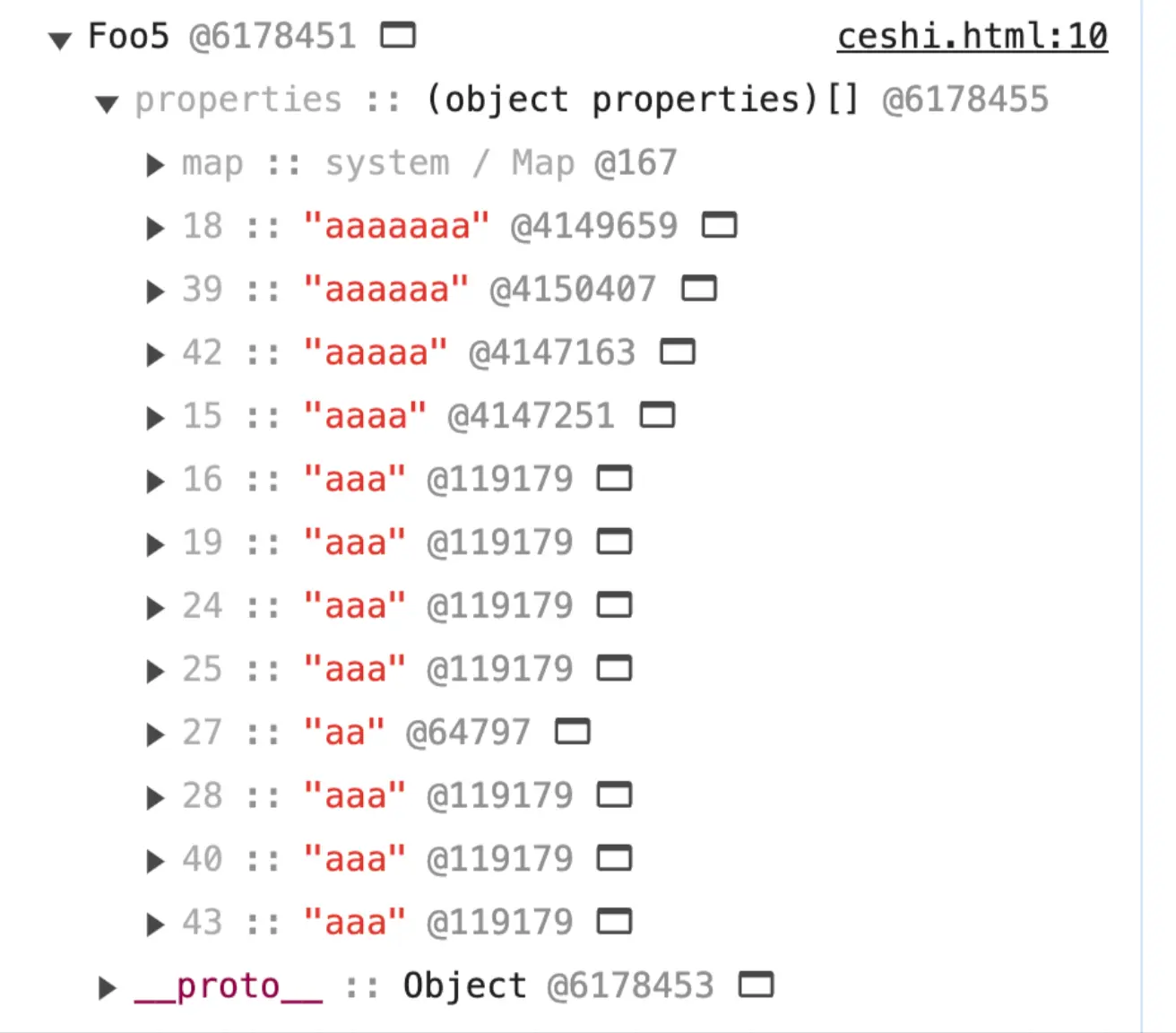 a 和 b 本身都是对象内属性。从快照可以看到,删除了 a.a 后,a 变成了慢属性,退回哈希存储。 所以 delete 操作会使对象的内部结构和性能产生影响。
a 和 b 本身都是对象内属性。从快照可以看到,删除了 a.a 后,a 变成了慢属性,退回哈希存储。 所以 delete 操作会使对象的内部结构和性能产生影响。 它会导致对象的隐藏类转变,从而使对象丧失其优化的属性访问能力,退化为慢属性存储。 所以我们在设计 JavaScript 对象结构时,应谨慎考虑属性的删除,以避免不必要的性能损失,尤其是在需要高性能属性访问的场景中。
结论与启示
- 属性分为命名属性和可索引属性,命名属性存放在 Properties 中,可索引属性存放在 Elements 中。
- 命名属性有三种不同的存储方式:对象内属性、快属性和慢属性,前两者通过线性查找进行访问,慢属性通过哈希存储的方式进行访问。
- 总是以相同的顺序初始化对象成员,能充分利用相同的隐藏类,进而提高性能。
- delete 操作会改变对象的结构,导致引擎将对象的存储方式降级为哈希表存储的方式,不利于 V8 的优化,应尽可能避免使用。
- 隐藏类的作用是确定对象属性在内存中的具体位置(相对于对象内存地址的偏移量),而 Properties 和 Elements 只是用于存储属性值的数据结构。隐藏类的存在使得 V8 引擎能够高效地查找和访问 Properties 和 Elements 中的值,从而提高 JavaScript 代码的执行速度。
V8 是怎么通过内联缓存来提升函数执行效率的?
function loadX(o) {
return o.x;
}
var o = { x: 1, y: 3 };
var o1 = { x: 3, y: 6 };
for (var i = 0; i < 90000; i++) {
loadX(o);
loadX(o1);
}V8 获取 o.x 的流程:查找对象 o 的隐藏类,再通过隐藏类查找 x属性偏移量,然后根据偏移量获取属性值
这段代码里 o.x 会被反复执行,那么查找流程也会被反复执行,那么 V8 有没有做这优化呢
内联缓存(Inline Cache,简称 IC)
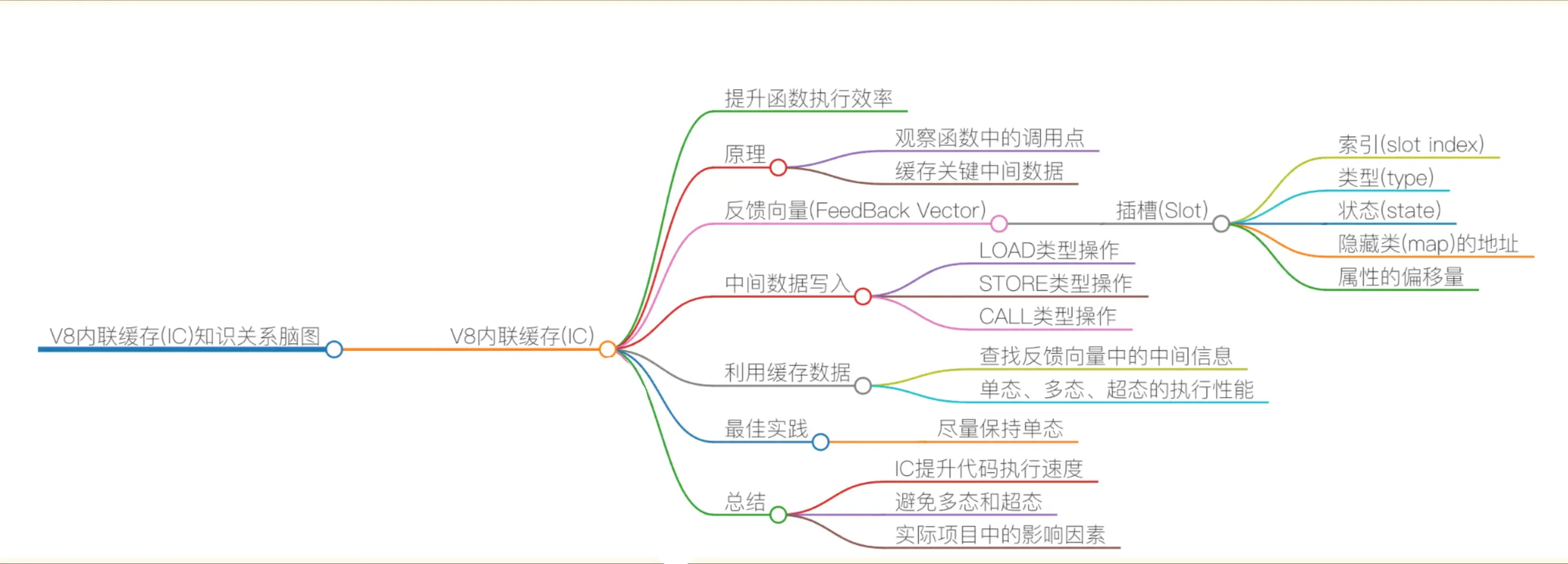
V8 在执行函数的过程中,会观察函数中的一些调用点(CallSite)上的关键数据(中间数据),然后将它们缓存起来,当下次再执行该函数时,V8 可以利用这些中间数据,节省再次获取这些数据的过程
IC 会为每个函数维护一个反馈向量 (FeedBack Vector),反馈向量记录了函数在执行过程中的一些关键的中间数据。关于函数和反馈向量的关系,如下图:
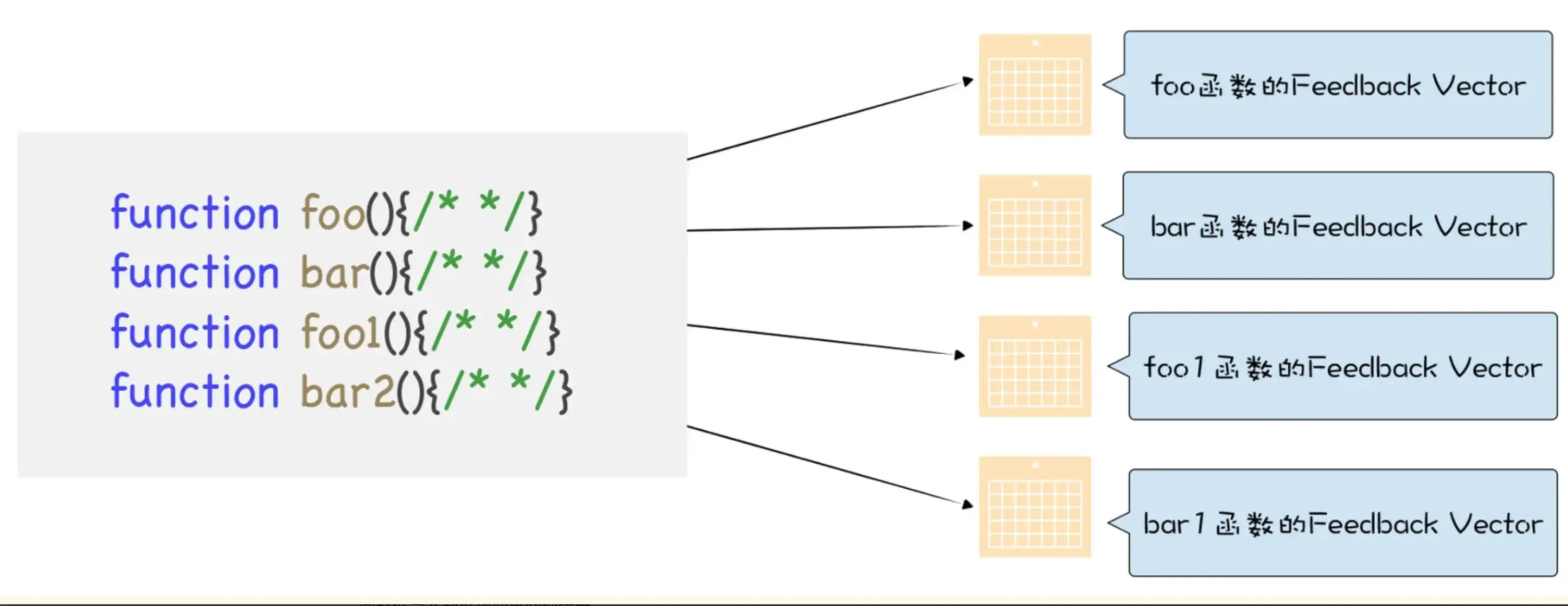
每个函数对应的反馈向量是一个表结构,有很多项,每一项称为一个插槽 (Slot)
function loadX(o) {
o.y = 4;
return o.x;
}当V8执行这段函数时,它判断 o.y = 4和 return o.x 是调用点 (CallSite),因为它们使用了对象和属性,那么 V8 会在 loadX 函数的反馈向量中为每个调用点分配一个插槽。
插槽中包括了:
- 插槽的索引 (slot index)
- 插槽的类型 (type)
- 插槽的状态 (state)
- 隐藏类 (map) 的地址
- 属性的偏移量
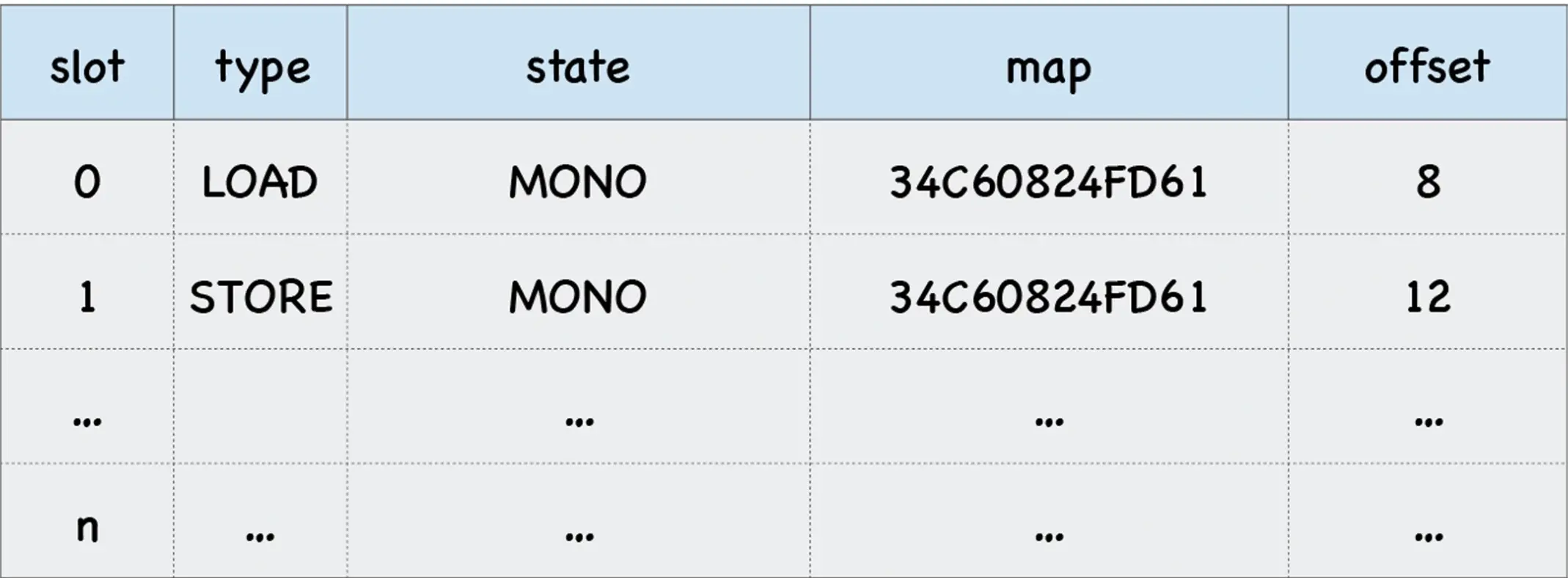
为什么函数的反馈向量表结构中要记录属性的偏移量,隐藏类不是包含了吗?
这是为了记录该函数在执行过程中,访问到对象的属性,是要记录读取过的,下次再次执行函数时,V8 可以直接从反馈向量表中读取属性的偏移量,而不需要再次根据对象的内存地址找到隐藏类,再计算属性的位置,这样可以大大提高属性访问的效率,因为不需要重复查找隐藏类的过程。
function loadX(o) {
return o.x;
}
loadX({ x: 1 });转成字节码
StackCheck // 检查是否溢出
LdaNamedProperty a0, [0], [0] // 取出函数参数 a0 的第一个属性值,并将属性值放到累加器中
Return // 返回累加器中的属性为什么 LdaNamedProperty a0, [0], [0] 是取出 a0 的第一个属性值而不是读取 x 属性?
首先,loadX 函数的参数是 o。在执行 loadX({x:1}) 时,o 就是 {x:1} 这个对象。
在 loadX 函数的字节码中,第二句是 LdaNamedProperty a0, [0], [0]。
这里的 a0 表示函数的第一个参数,也就是 o 这个对象。
[0] 表示要读取 o 对象的第一个属性。但这里并不是直接读取 x 属性,而是先读取 o 对象的第一个属性,然后将其值放到累加器中。
为什么不直接读取 x 属性呢?这是因为 V8 在执行 LdaNamedProperty 时,需要先将属性名转换为属性索引。
在这个例子中,o 对象只有一个属性 x。所以 V8 先读取 o 的第一个属性,也就是 x。
第三个[0]就和反馈向量有关,它表示将 LdaNamedProperty 操作的中间数据写入到反馈向量中,方括号中间的 0 表示写入反馈向量的第一个插槽中
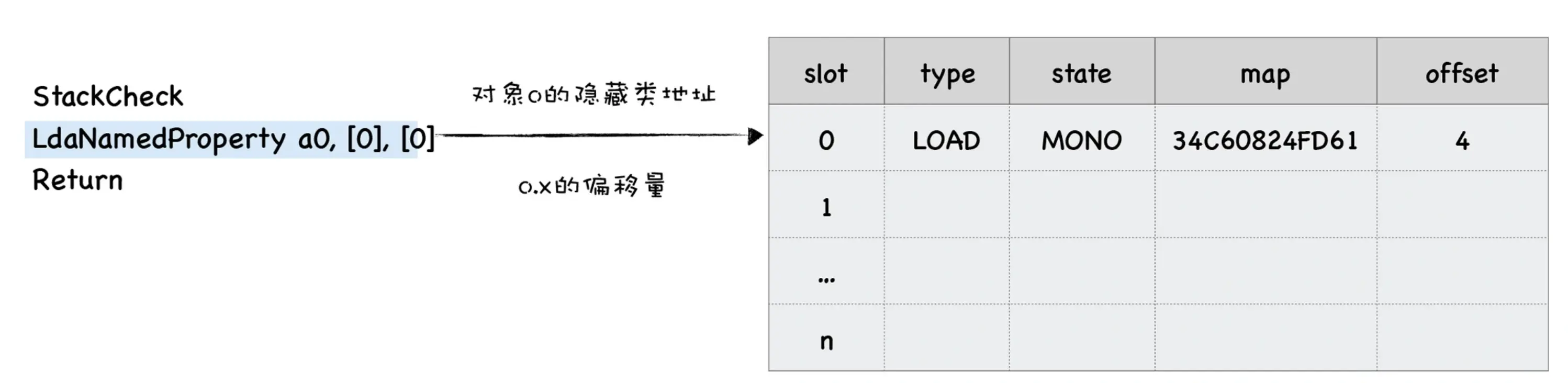
然后,V8 会将这个属性值放到累加器中,供后续的 Return 指令使用。
多态和超态
function loadX(o) {
return o.x;
}
var o = { x: 1, y: 3 };
var o1 = { x: 3, y: 6, z: 4 };
for (var i = 0; i < 90000; i++) {
loadX(o);
loadX(o1);
}对象 o 和 o1 的形状是不同的,这意味着 V8 为它们创建的隐藏类也是不同的。
第一次执行时 loadX 时,V8 会将 o 的隐藏类记录在 loadX 函数的反馈向量中,并记录属性 x 的偏移量。那么当再次调用 loadX 函数时,V8 会取出 loadX 函数的反馈向量表中记录的隐藏类,并和新的 o1 的隐藏类进行比较,发现不是一个隐藏类,那么此时 V8 就无法使用反馈向量中记录的偏移量信息了。
面对这种情况,V8 会选择将新的隐藏类也记录在反馈向量中,同时记录属性值的偏移量,这时,反馈向量中的第一个槽里就包含了两个隐藏类和偏移量。如下图: 
当 V8 再次执行 loadX 函数中的 o.x 语句时,同样会查找反馈向量表,发现第一个槽中记录了两个隐藏类。这时,V8 需要额外做一件事,那就是拿这个新的隐藏类和第一个插槽中的两个隐藏类来一一比较,如果新的隐藏类和第一个插槽中某个隐藏类相同,那么就使用该命中的隐藏类的偏移量。如果没有相同的呢?同样将新的信息添加到反馈向量的第一个插槽中。
一个反馈向量的一个插槽中可以包含多个隐藏类的信息:
- 如果一个插槽中只包含 1 个隐藏类,那么我们称这种状态为单态 (monomorphic);
- 如果一个插槽中包含了 2 ~ 4 个隐藏类,那我们称这种状态为多态 (polymorphic);
- 如果一个插槽中超过 4 个隐藏类,那我们称这种状态为超态 (magamorphic)。
如果函数 loadX 的反馈向量中存在多态或者超态的情况,执行效率肯定要低于单态的,比如当执行到 o.x 的时候,V8 会查询反馈向量的第一个插槽,发现里面有多个 map 的记录,那么 V8 就需要取出 o 的隐藏类,来和插槽中记录的隐藏类一一比较,如果记录的隐藏类越多,那么比较的次数也就越多,这就意味着执行效率越低。
比如插槽中包含了 2 ~ 4 个隐藏类,那么可以使用线性结构来存储,如果超过 4 个,那么 V8 会采取 hash 表的结构来存储,这无疑会拖慢执行效率。单态、多态、超态等三种情况的执行性能如下图所示: 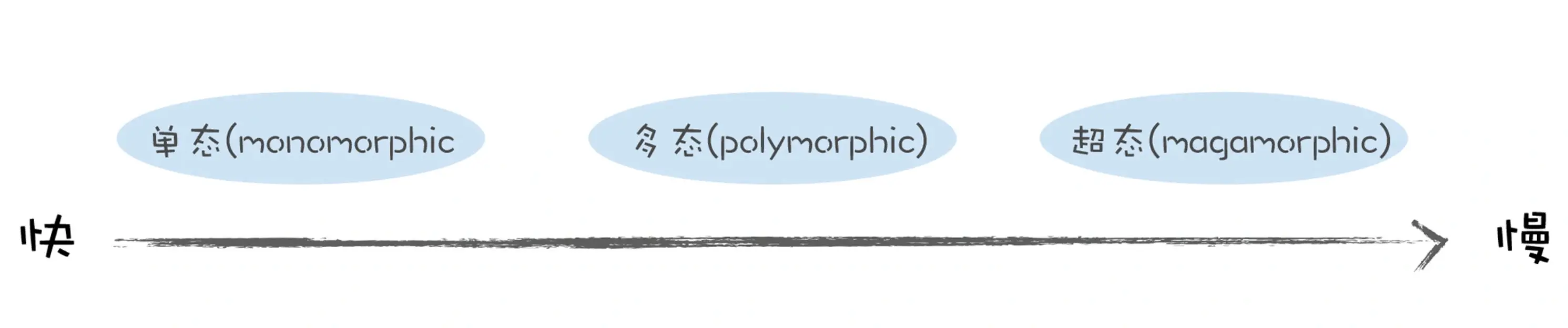
尽量保持单态
IC 只是为每个函数添加了一个缓存,当第一次执行该函数时,V8 会将函数中的存储、加载和调用相关的中间结果保存到反馈向量中。当再次执行时,V8 就要去反馈向量中查找相关中间信息,如果命中了,那么就直接使用中间信息。
总的来说,那就是单态的性能优于多态和超态,所以我们需要稍微避免多态和超态的情况。要避免多态和超态,那么就尽量默认所有的对象属性是不变的,比如你写了一个 loadX(o) 的函数,那么当传递参数时,尽量不要使用多个不同形状的 o 对象。
隐藏类、element 、 property 、 内联缓存的关系
隐藏类只是记录了对象属性的位置信息如偏移量,而 Property 还有 Element 才是实际存储对象数据的具体地方。
有了内联缓存的信息,就不用每次去读取隐藏类然后完整遍历 element 和 property 了,而是根据内联缓存的信息快速查找
隐藏类、element 、 property 、 内联缓存协同工作共同构成了 V8 中高效的对象表示和访问机制