浏览器视角:页面是如何从 0 到 1 加载的
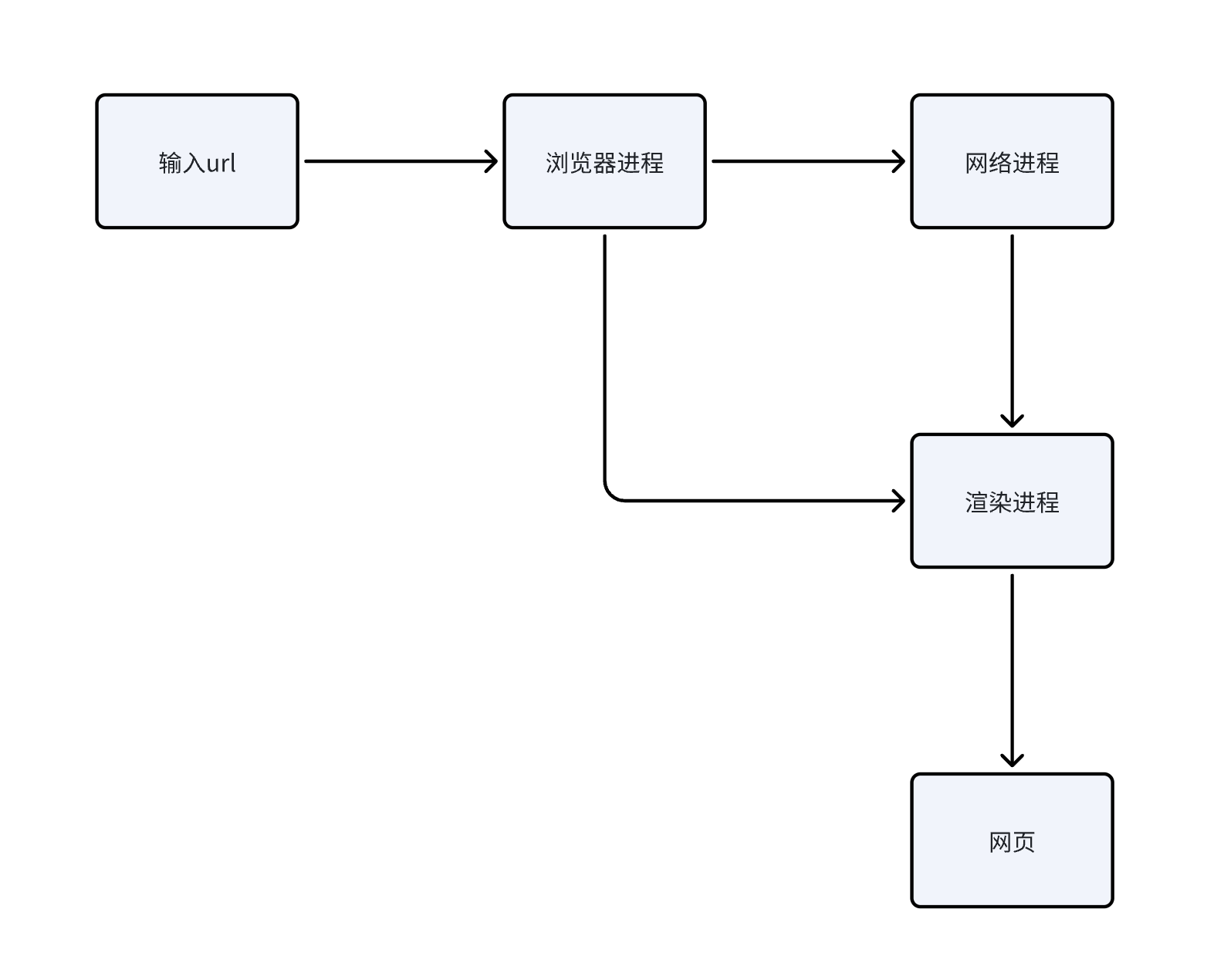
1. 用户输入 URL 并回车

用户在浏览器地址栏输入 URL 并按下回车键。
2. 浏览器进程检查 url,组装协议,构成完整的 url
浏览器会根据用户输入的信息判断是搜索还是网址,如果是搜索内容,就将搜索内容+默认搜索引擎合成新的 URL;如果用户输入的内容符合 URL 规则,浏览器就会根据 URL 协议,在这段内容上加上协议合成合法的 URL 用户输入完内容,按下回车键,浏览器导航栏显示 loading 状态,但是页面还是呈现前一个页面,这是因为新页面的响应数据还没有获得
3. 发送请求到网络进程
浏览器进程通过进程间通信(IPC)将 URL 请求发送给网络进程。 
4. 网络进程处理请求
网络进程接收到 URL 请求后:
- 检查本地缓存:
- 如果缓存中有该请求的资源,则将该资源返回给浏览器主进程。
- 如果没有,则进行网络请求,流程如下: 如果有则将该资源返回给浏览器主进程 如果没有,网络进程向 web 服务器发起 http 请求(网络请求),请求流程如下:
4.1 进行 DNS 解析,获取服务器 ip 地址,端口(http 默认 80 https 默认 443 如果不是默认的要咨询服务商)
4.2 利用 ip 地址和服务器建立 tcp 连接
4.3 构建并发送请求头信息
4.4 服务器响应后,网络进程接收响应头和响应信息,并解析响应内容
5. 网络进程解析响应流程;
- 状态码检查:
- 如果是 301/302,进行重定向处理,重新发起请求。
- 如果是 200,继续处理请求。
- 处理 200 响应:
- 检查响应类型
Content-Type: - 如果是字节流类型,提交给下载管理器结束导航流程。 - 如果是 HTML,则通知浏览器进程准备渲染进程进行渲染。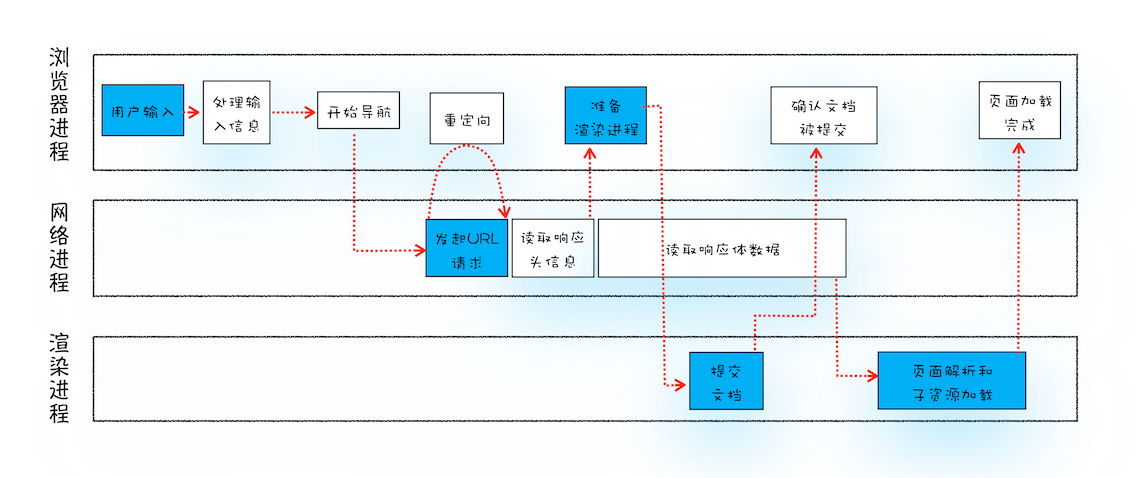
- 检查响应类型
6. 准备渲染进程
浏览器进程检查当前 URL 是否和之前的渲染进程根域名相同。如果相同,则复用原来的渲染进程;如果不同,则开启新的渲染进程。
7. 传输数据、更新状态
- 渲染进程准备好后,浏览器进程向渲染进程发起“提交文档”的消息。
- 渲染进程接收到消息后,与网络进程建立传输数据的“管道”。
- 渲染进程接收完数据后,向浏览器发送“确认提交”。
- 浏览器进程接收到确认消息后,更新浏览器界面状态,显示新页面。
8. 渲染页面内容
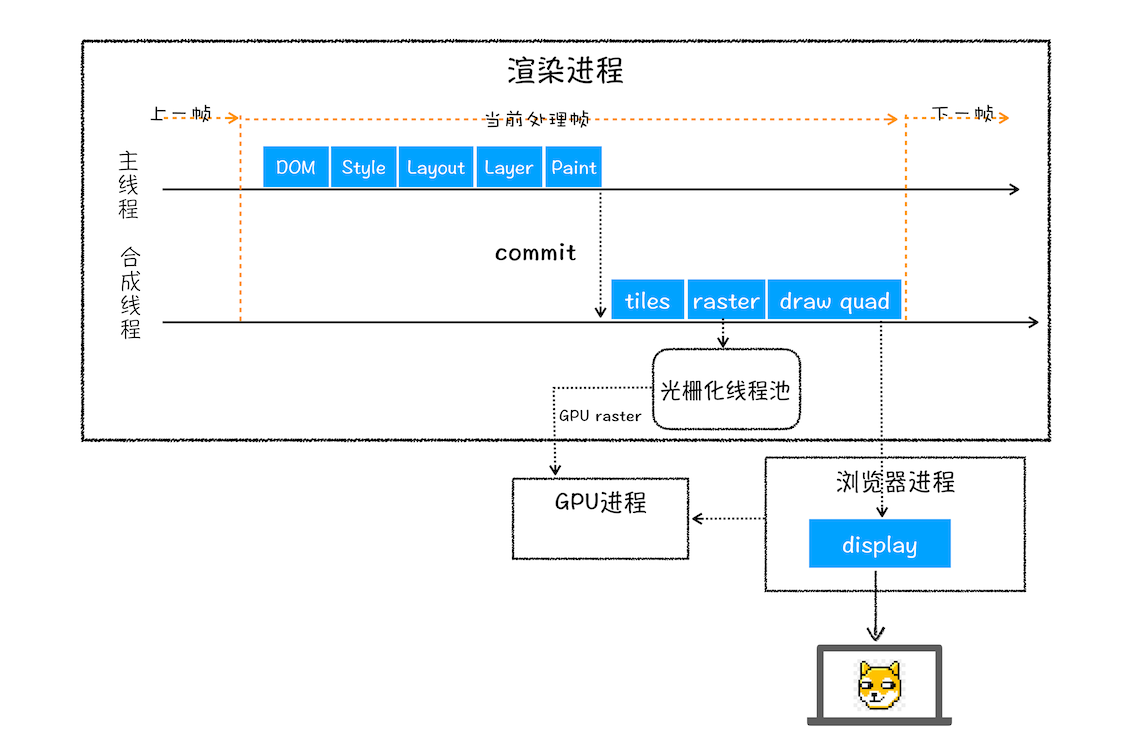
结合上图,一个完整的渲染流程大致可总结为如下:
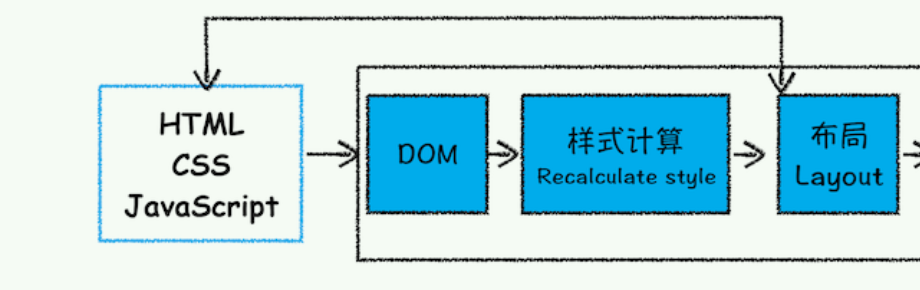
渲染进程将 HTML 内容转换为 DOM 树结构。
渲染引擎将 CSS 样式表转化为浏览器可以理解的
styleSheets。计算 DOM 节点的样式,创建布局树,计算元素的布局信息。
对布局树进行分层,生成分层树,生成绘制列表,并将其提交到渲染进程中的合成线程。以下是分层图:
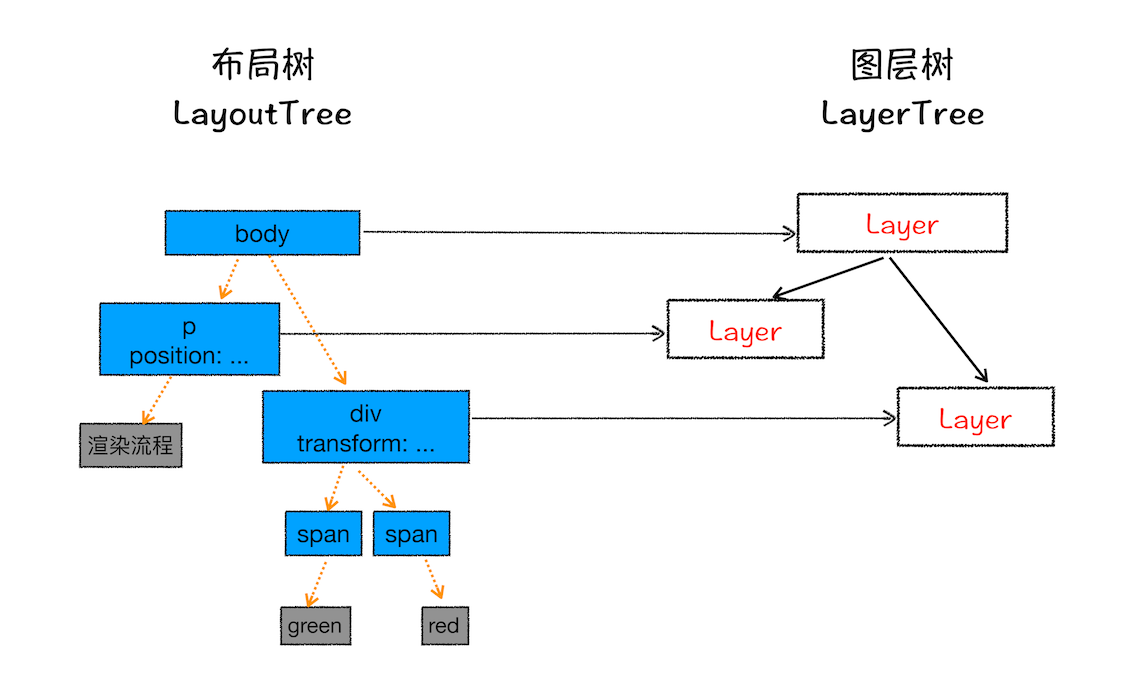
最终每一个节点都会直接或者间接地从属于一个层 渲染引擎会对图层树中的每个图层进行绘制,其中把一个图层的绘制拆分成很多小的绘制指令,然后再把这些指令按照顺序组成一个待绘制列表 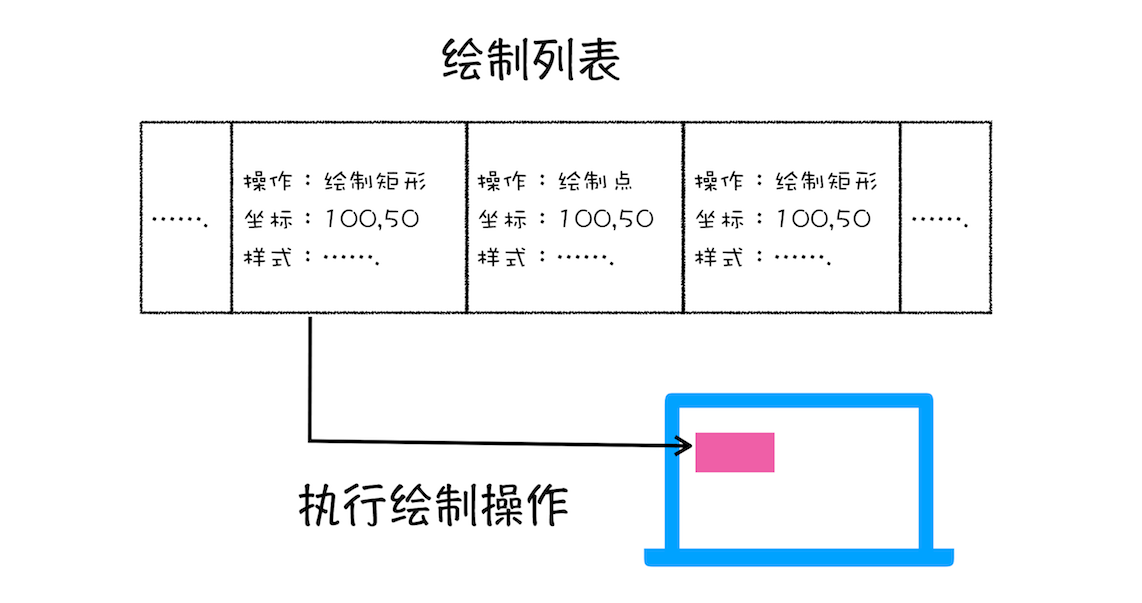
- 栅格化(Rasterization)
接下来就是绘制图层,绘制工作是由渲染进程中的合成线程进行处理的 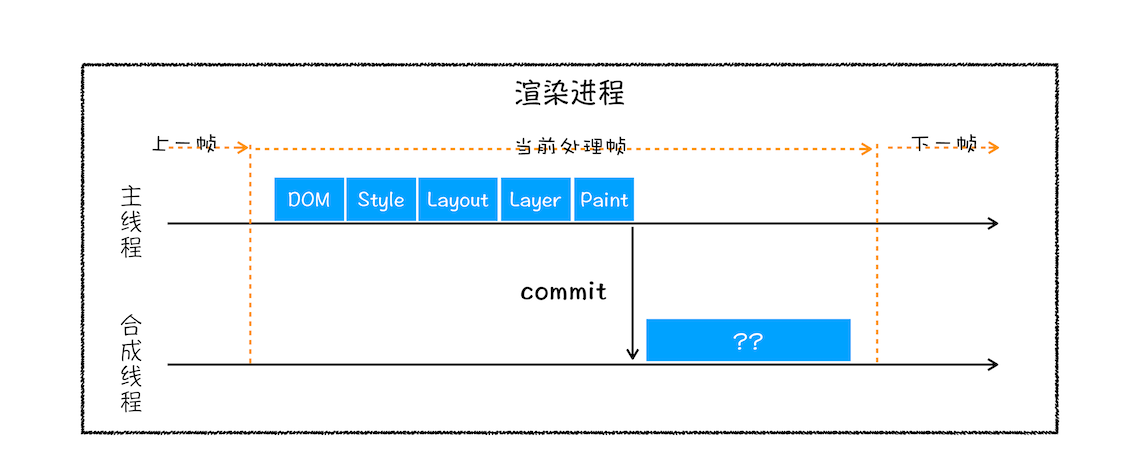 因为一个页面很大,所以不能一下子加载整个页面,基于这个原因,合成线程会将图层划分为图块(tile) 所以优先加载视口周围的模块
因为一个页面很大,所以不能一下子加载整个页面,基于这个原因,合成线程会将图层划分为图块(tile) 所以优先加载视口周围的模块 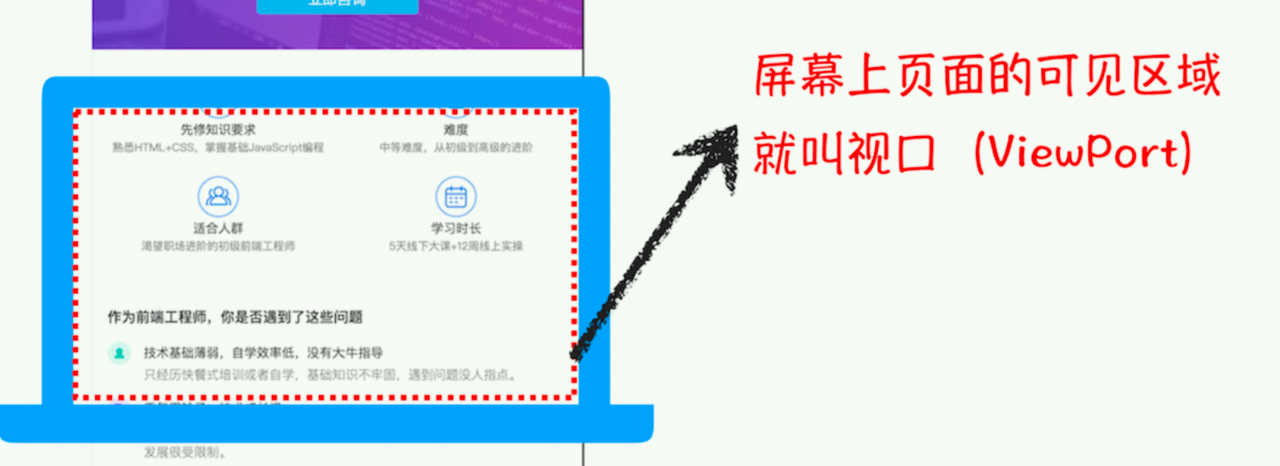 合成线程会按照视口附近的图块来优先生成位图(位图是一种由像素组成的图像格式,也被称为光栅图像。在位图图像中,每个像素都有自己的颜色值和位置,这些像素按照一定的排列顺序组成图像。位图图像通常以文件格式如 JPEG、PNG 或 BMP 存储。),实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图。而图块是栅格化执行的最小单位。渲染进程维护了一个栅格化的线程池,所有的图块栅格化都是在线程池内执行的,运行方式如下图所示:
合成线程会按照视口附近的图块来优先生成位图(位图是一种由像素组成的图像格式,也被称为光栅图像。在位图图像中,每个像素都有自己的颜色值和位置,这些像素按照一定的排列顺序组成图像。位图图像通常以文件格式如 JPEG、PNG 或 BMP 存储。),实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图。而图块是栅格化执行的最小单位。渲染进程维护了一个栅格化的线程池,所有的图块栅格化都是在线程池内执行的,运行方式如下图所示: 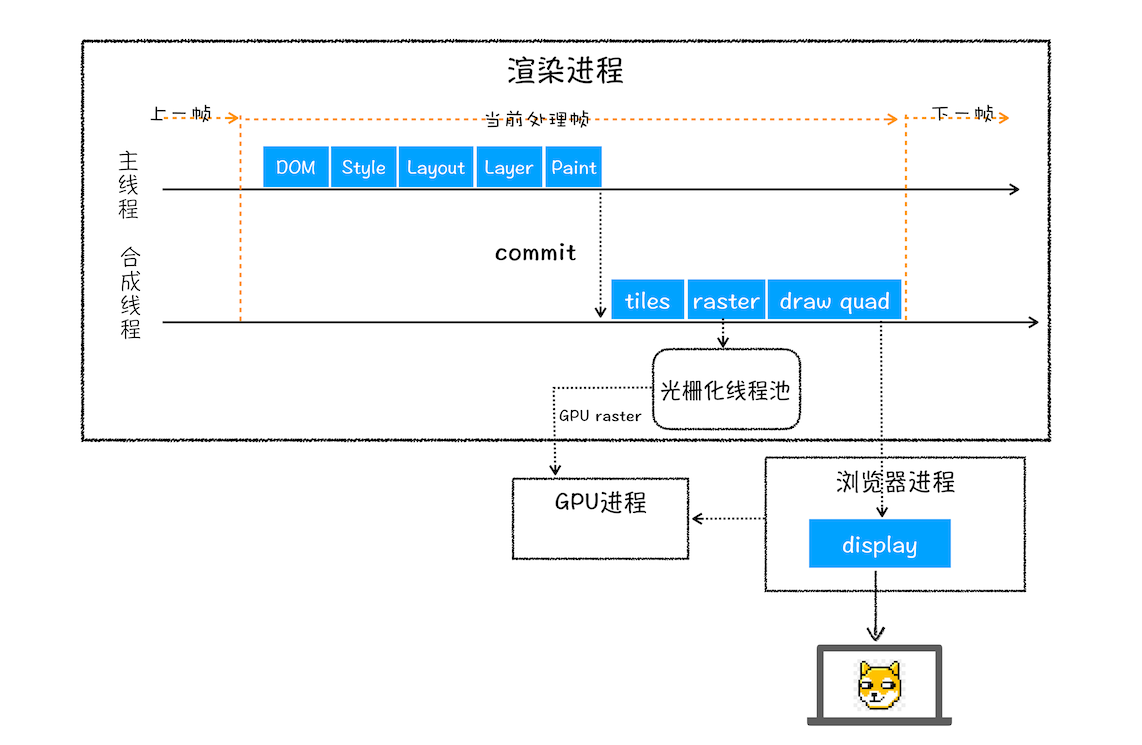 通常,栅格化过程都会使用 GPU 来加速生成,利用 gpu 的并行计算能力,并行处理多个栅格化任务来加速栅格化过程,本质还是在渲染进程中的栅格化线程池中执行位图的生成工作,使用 GPU 生成位图的过程叫快速栅格化,或者 GPU 栅格化,生成的位图被保存在 GPU 内存中,然后再交给浏览器 Compositor 进程并完成最终的合成和渲染工作,最终将渲染结果提交给 GPU 进程的后缓冲区,等待被显示到屏幕上
通常,栅格化过程都会使用 GPU 来加速生成,利用 gpu 的并行计算能力,并行处理多个栅格化任务来加速栅格化过程,本质还是在渲染进程中的栅格化线程池中执行位图的生成工作,使用 GPU 生成位图的过程叫快速栅格化,或者 GPU 栅格化,生成的位图被保存在 GPU 内存中,然后再交给浏览器 Compositor 进程并完成最终的合成和渲染工作,最终将渲染结果提交给 GPU 进程的后缓冲区,等待被显示到屏幕上
详细过程:
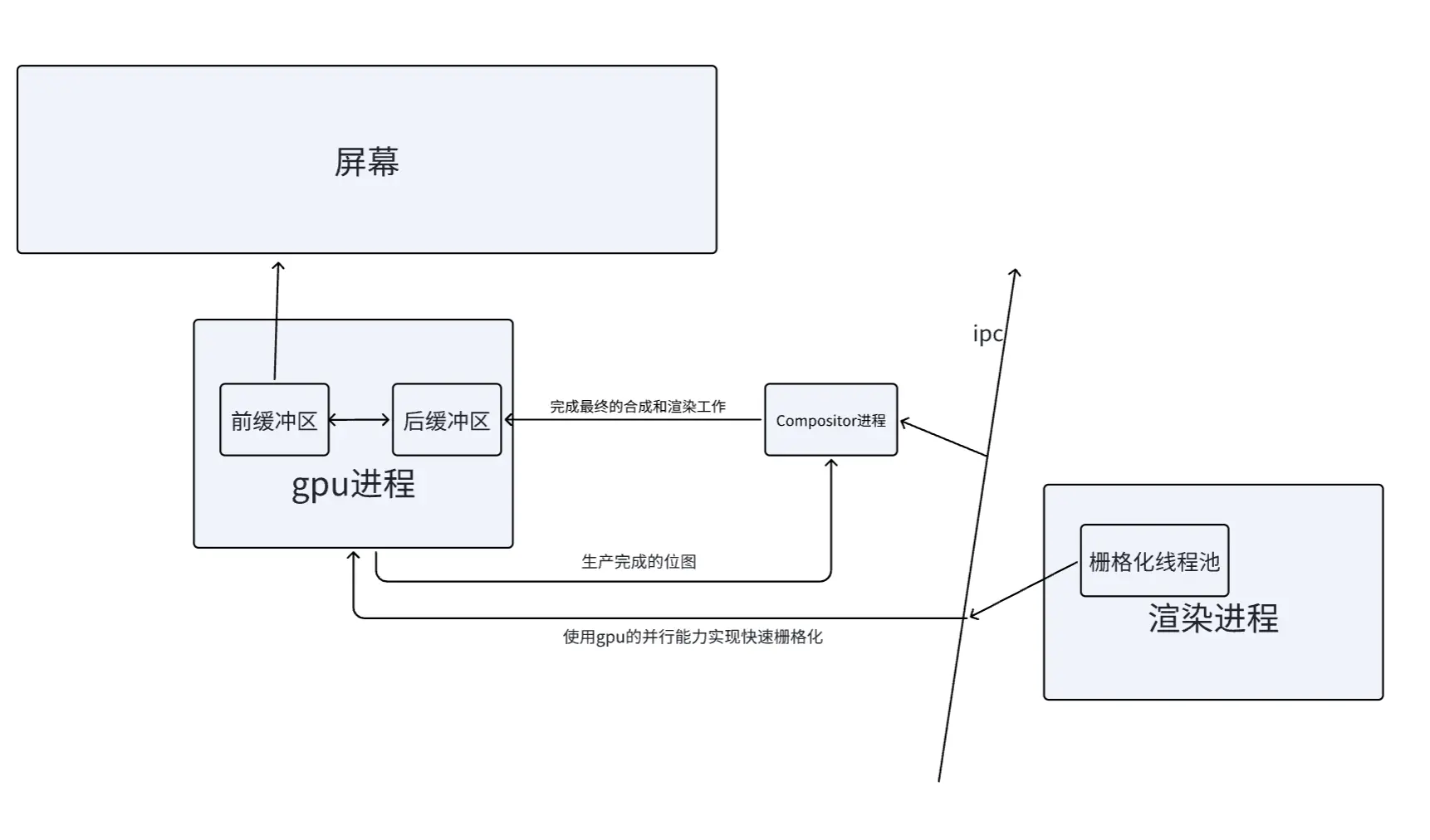
- 渲染进程的合成线程将合成的页面图片发送给浏览器进程。
- 浏览器进程接收到页面图片后会发送给 gpu 进程,gpu 进程会将其存储在后缓冲区中。
- 当下一帧渲染时,前缓冲区和后缓冲区会进行交换。
- 显示器从 GPU 的前缓冲区中获取到页面图片,并将其显示在屏幕上。
注意
快速栅格化是使用 gpu 进程来处理,生成的位图保存在 gpu 进程内存中,最终还是先要交给浏览器进程,然后浏览器进程再交给 gpu 进程,因为浏览器主进程还需要做额外的管理和调度,以及和渲染相关的任务,如页面交互,js 执行等)总之,开启 GPU 栅格化确实可以让位图直接在 GPU 内存中生成,但这些位图仍然需要通过浏览器进程来进行管理和调度,最终再由浏览器主进程交给 GPU 进程控制显示。这样的设计可以确保渲染流程的高效和安全。
Q&A
当浏览器接收 HTML 页面时,JavaScript 脚本对 DOM 解析有什么影响?
当从服务器接收 HTML 页面的第一批数据时,DOM 解析器就开始工作了。在解析过程中,如果遇到了 JavaScript 脚本,如下所示:
<html>
<body>
不一样的少年
<script>
document.write('--foo');
</script>
</body>
</html>那么 DOM 解析器会先执行 JavaScript 脚本,执行完成之后,再继续往下解析。
那么第二种情况复杂点了,我们内联的脚本替换成 js 外部文件,如下所示:
<html>
<body>
不一样的少年
<script type="text/javascript" src="foo.js"></script>
</body>
</html>
```这种情况下,当解析到 JavaScript 的时候,会先暂停 DOM 解析,并下载 foo.js 文件,下载完成之后执行该段 JS 文件,然后再继续往下解析 DOM。这就是 JavaScript 文件为什么会阻塞 DOM 渲染。推荐使用异步加载 js 脚本,使用 async 或 defer 属性。
如果下载 CSS 文件阻塞了,会阻塞 DOM 树的合成吗?
<html>
<head>
<style type="text/css" src="theme.css" />
</head>
<body>
<p>极客时间</p>
<script>
let e = document.getElementsByTagName('p')[0];
e.style.color = 'blue';
</script>
</body>
</html>
```当 JavaScript 中访问了某个元素的样式,那么这时候就需要等待这个样式被下载完成才能继续往下执行,所以在这种情况下,CSS 也会阻塞 DOM 的解析。所以下载 CSS 文件会阻塞 DOM 树的合成。 可以使用内联 css 或者对 css 文件进行压缩、异步加载来避免阻塞 DOM 树合成。