网络
http1.1 相对于 1.0 增加了持久化连接,同一个域名支持 6 个 tcp 链接
http1.1
目前浏览器中对于同一个域名,默认允许同时建立 6 个 TCP 持久连接“,那就是如果浏览器同时请求 n 个不同域名的后台服务器,那就是允许同时建立 n * 6 个 TCP 持久连接 在一个 tcp 通道中,后一个请求必须要等待前一个请求完成才能进行,也就是同一时刻只允许 tcp 通道中只有一个请求在进行,这就是对头阻塞
TCP 慢启动
慢启动:一旦一个 TCP 连接建立之后,就进入了发送数据状态,刚开始 TCP 协议会采用一个非常慢的速度去发送数据,然后慢慢加快发送数据的速度,直到发送数据的速度达到一个理想状态,我们把这个过程称为慢启动。
HTTP/1.1 所存在的一些主要问题: 慢启动和 TCP 连接之间相互竞争带宽是由于 TCP 本身的机制导致的, 而队头阻塞是由于 HTTP/1.1 的机制导致的。
为什么 tcp 机制会有慢启动?
避免网络堵塞而设计的,提高网络传输效率 TCP 协议中的慢启动是为了避免网络拥塞而设计的。在 TCP 连接建立时,发送方会先发送少量的数据包,然后逐渐增加发送数据包的数量,直到网络达到拥塞点。如果一开始就发送大量的数据包,可能会导致网络拥塞,造成数据包的丢失和重传,从而降低网络的传输效率
http2
基于此,HTTP/2 的思路就是一个域名只使用一个 TCP 长连接来传输数据,这样整个页面资源的下载过程只需要一次慢启动,同时也避免了多个 TCP 连接竞争带宽所带来的问题。另外,就是队头阻塞的问题,等待请求完成后才能去请求下一个资源,这种方式无疑是最慢的,所以 HTTP/2 需要实现资源的并行请求,也就是任何时候都可以将请求发送给服务器,而并不需要等待其他请求的完成,然后服务器也可以随时返回处理好的请求资源给浏览器。 所以,HTTP/2 的解决方案可以总结为:一个域名只使用一个 TCP 长连接和消除队头阻塞问题。可以参考下图
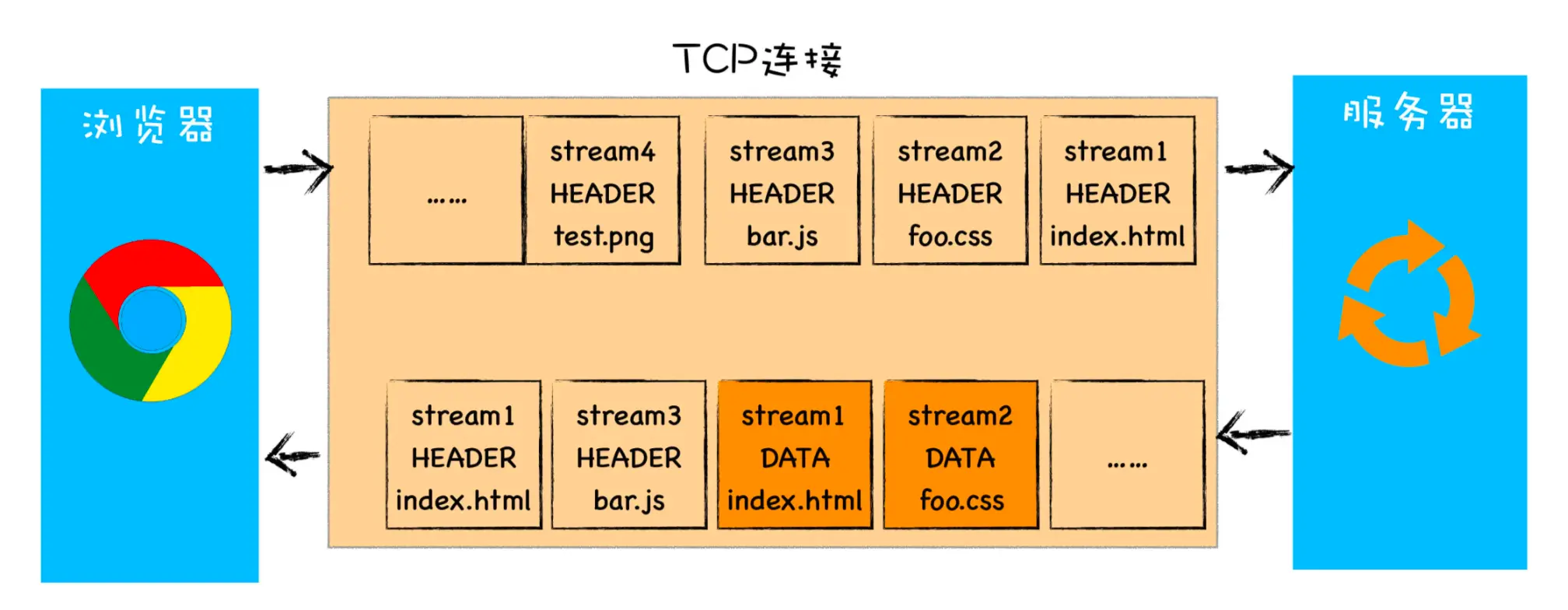
该图就是 HTTP/2 最核心、最重要且最具颠覆性的多路复用机制
多路复用的实现
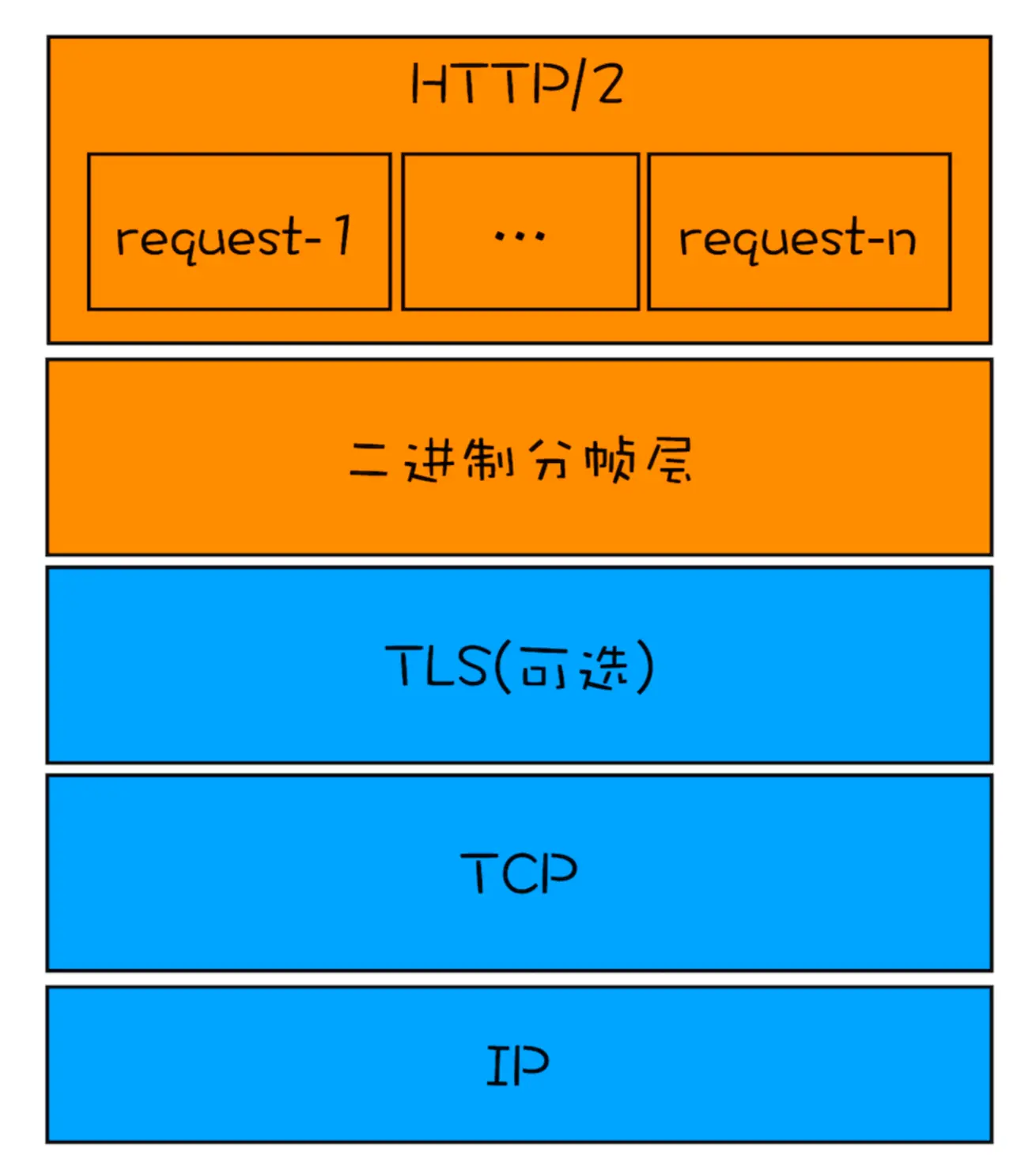 从图中可以看出,在协议栈中,HTTP/2 添加了一个二进制分帧层,那我们就结合图来分析下 HTTP/2 的请求和接收过程。
从图中可以看出,在协议栈中,HTTP/2 添加了一个二进制分帧层,那我们就结合图来分析下 HTTP/2 的请求和接收过程。 - 首先,浏览器准备好请求数据,包括了请求行、请求头等信息,如果是 POST 方法,那么还要有请求体。
- 这些数据经过二进制分帧层处理之后,会被转换为一个个带有请求 ID 编号的帧 ,通过协议栈将这些帧发送给服务器。
- 服务器接收到所有帧之后,会将所有相同 ID 的帧合并为一条完整的请求信息。
- 然后服务器处理该条请求,并将处理的响应行、响应头和响应体分别发送至二进制分帧层。
- 同样,二进制分帧层会将这些响应数据转换为一个个带有请求 ID 编号的帧,经过协议栈发送给浏览器。 浏览器接收到响应帧之后,会根据 ID 编号将帧的数据提交给对应的请求。
http2 特性
- 可以设置请求的优先级
- 服务器推送(当用户请求一个 HTML 页面之后,服务器知道该 HTML 页面会引用几个重要的 JavaScript 文件和 CSS 文件,那么在接收到 HTML 请求之后,附带将要使用的 CSS 文件和 JavaScript 文件一并发送给浏览器,这样当浏览器解析完 HTML 文件之后,就能直接拿到需要的 CSS 文件和 JavaScript 文件,这对首次打开页面的速度起到了至关重要的作用。)HTTP/2 的服务器推送更适用于静态资源的推送,而 WebSocket 的服务器推送更适用于实时消息的推送。
- 头部压缩(在浏览器发送请求的时候,基本上都是发送 HTTP 请求头,很少有请求体的发送,所以头部压缩可以提高传输效率)
总结:多路复用是通过在协议栈中添加二进制分帧层来实现的,有了二进制分帧层还能够实现请求的优先级、服务器推送、头部压缩等特性,从而大大提升了文件传输效率
http2 依然是建立在 tcp 链接上的,所以 tcp 还是会有对头阻塞的问题,这个对头阻塞是 tcp 的对头阻塞,因为 tcp 机制是从发送端按顺序将数据一一发送给接收端的,所以只要传输过程中出现一个包丢失了,那么整个 tcp 连接将会处于暂停状态,需要等待丢失的 tcp 包重新连接上才能继续传输数据。
数据包丢失 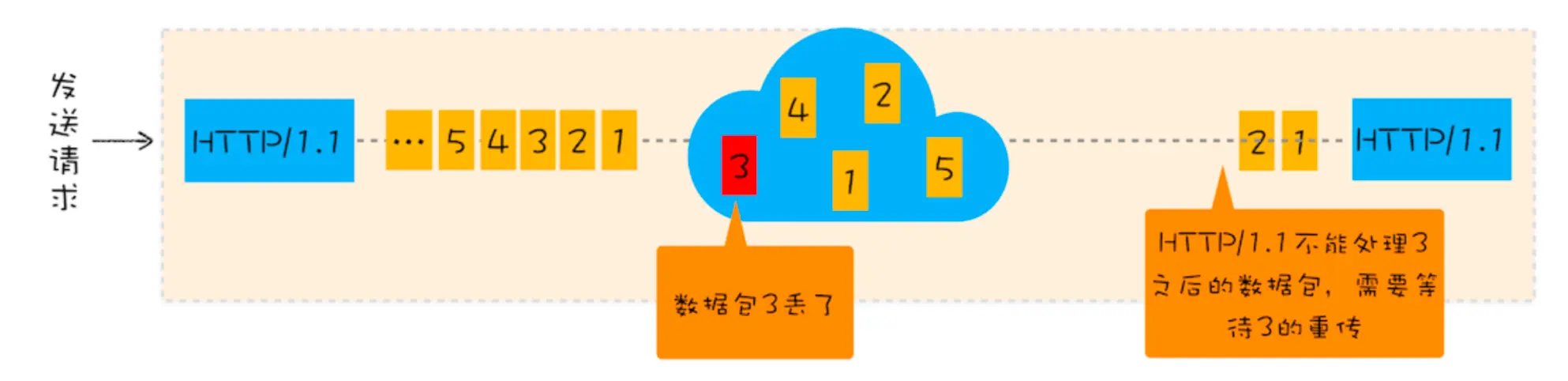
在 TCP 传输过程中,由于单个数据包的丢失而造成的阻塞称为 TCP 上的队头阻塞。
tcp 协议有两个缺点:一个是 tcp 对头阻塞,一个是建立连接延迟。
为什么不改 tcp 协议?
因为 tcp 协议的僵化
中间设备的僵化,大量的中间设备一旦更新协议可能会导致不兼容问题,从而导致数据包的丢失。
操作系统的更新滞后性,,因为 tcp 协议是通过操作系统内核来实现的,操作系统的升级又是滞后于应用程序的,随着应用程序的快速发展,因此想要自由的更新 tcp 协议比较麻烦 (当我们使用一个应用程序进行网络通信时,比如浏览器访问网页,实际上是通过操作系统提供的网络功能来完成的。操作系统内核中实现了 TCP 协议,应用程序只能使用这个协议,无法修改它。类比一下,操作系统就像一台大机器,而应用程序就是在这台机器上运行的小工具。
现在假设我们需要对 TCP 协议进行一些改进,以提高网络通信的效率或者适应新的网络环境。这就好比我们想要对这台大机器进行升级,以提升它的性能或者适应新的需求。 然而,操作系统的更新通常会滞后于软件的更新。就好比这台大机器的升级需要经过一系列的审批和测试,而且还要考虑到机器的稳定性和兼容性。因此,要自由地更新内核中的 TCP 协议是非常困难的,就像要自由地对这台大机器进行升级一样困难。 这种滞后性导致了 TCP 协议的僵化。随着互联网的发展和应用需求的变化,我们可能需要对 TCP 协议进行一些改进和优化,但由于操作系统更新的滞后性,这些改进和优化可能无法及时地应用到 TCP 协议的实现中,从而导致协议的僵化。)
http3
QUIC 协议(Quick UDP Internet Connections, 快速 UDP 网络连接 ) 为了解决 tcp 协议导致的问题,http3 采用 QUIC 协议,这个协议并没有采用 tcp 进行连接
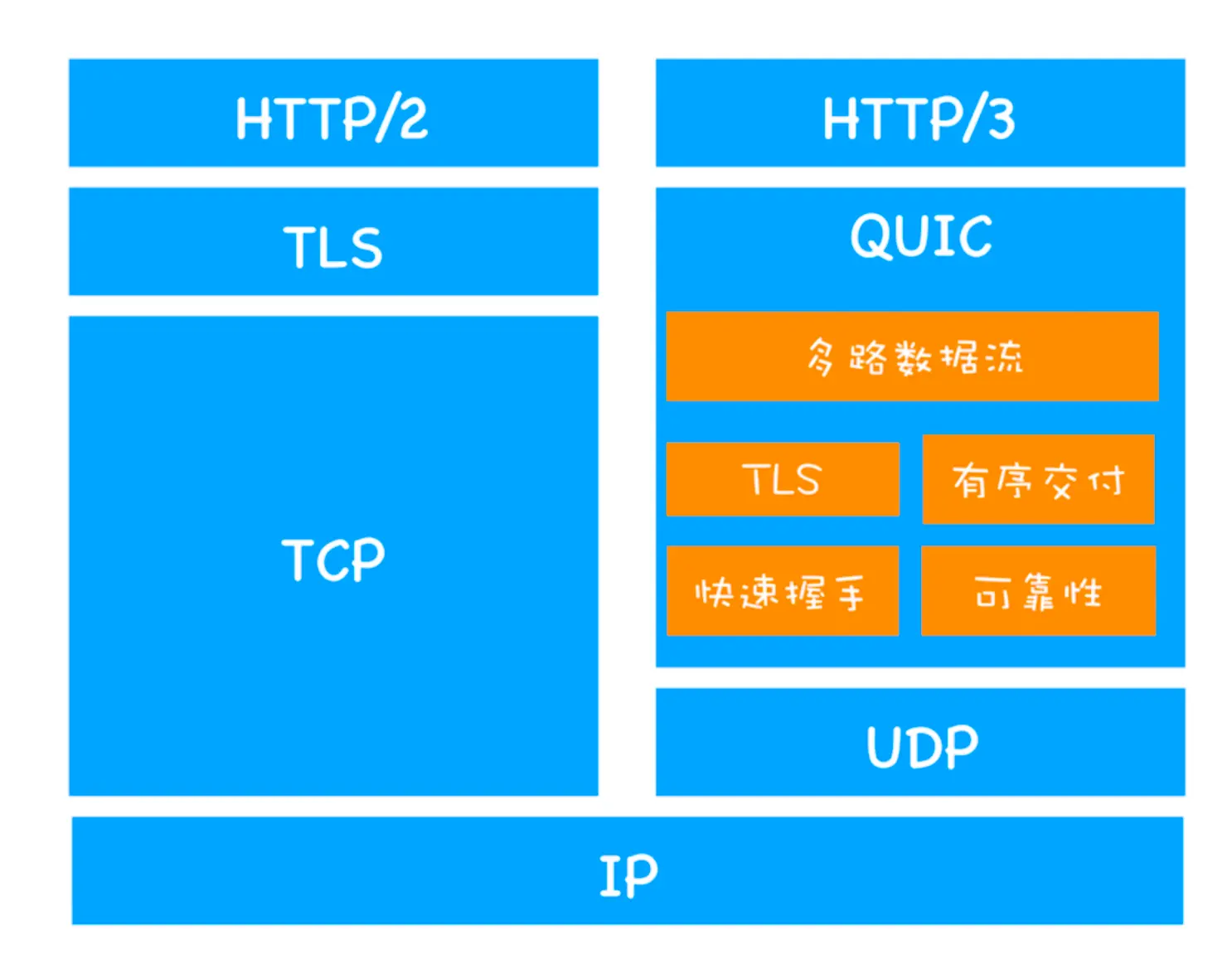 1. 实现了类似 TCP 的流量控制、传输可靠性的功能。虽然 UDP 不提供可靠性的传输,但 QUIC 在 UDP 的基础之上增加了一层来保证数据可靠性传输。它提供了数据包重传、拥塞控制以及其他一些 TCP 中存在的特性。
1. 实现了类似 TCP 的流量控制、传输可靠性的功能。虽然 UDP 不提供可靠性的传输,但 QUIC 在 UDP 的基础之上增加了一层来保证数据可靠性传输。它提供了数据包重传、拥塞控制以及其他一些 TCP 中存在的特性。 集成了 TLS 加密功能。目前 QUIC 使用的是 TLS1.3,相较于早期版本 TLS1.3 有更多的优点,其中最重要的一点是减少了握手所花费的 RTT 个数。
实现了 HTTP/2 中的 多路复用功能。和 TCP 不同,QUIC 实现了在同一物理连接上可以有多个独立的逻辑数据流(如下图)。实现了数据流的单独传输,就解决了 TCP 中队头阻塞的问题。
实现了 快速握手功能。由于 QUIC 是基于 UDP 的,所以 QUIC 可以实现使用 0-RTT 或者 1-RTT 来建立连接,这意味着 QUIC 可以用最快的速度来发送和接收数据,这样可以大大提升首次打开页面的速度。
为什么不采用 http3?
总体上就是操作系统和中间设备对于 udp 的优化没有 tcp 那么好,导致这个协议普及有点困难
- 服务器和浏览器端都没有对 HTTP/3 提供比较完整的支持
- 部署 HTTP/3 也存在着非常大的问题。因为系统内核对 UDP 的优化远远没有达到 TCP 的优化程度,这也是阻碍 QUIC 的一个重要原因
- 中间设备僵化的问题。这些设备对 UDP 的优化程度远远低于 TCP,据统计使用 QUIC 协议时,大约有 3%~ 7% 的丢包率。
https
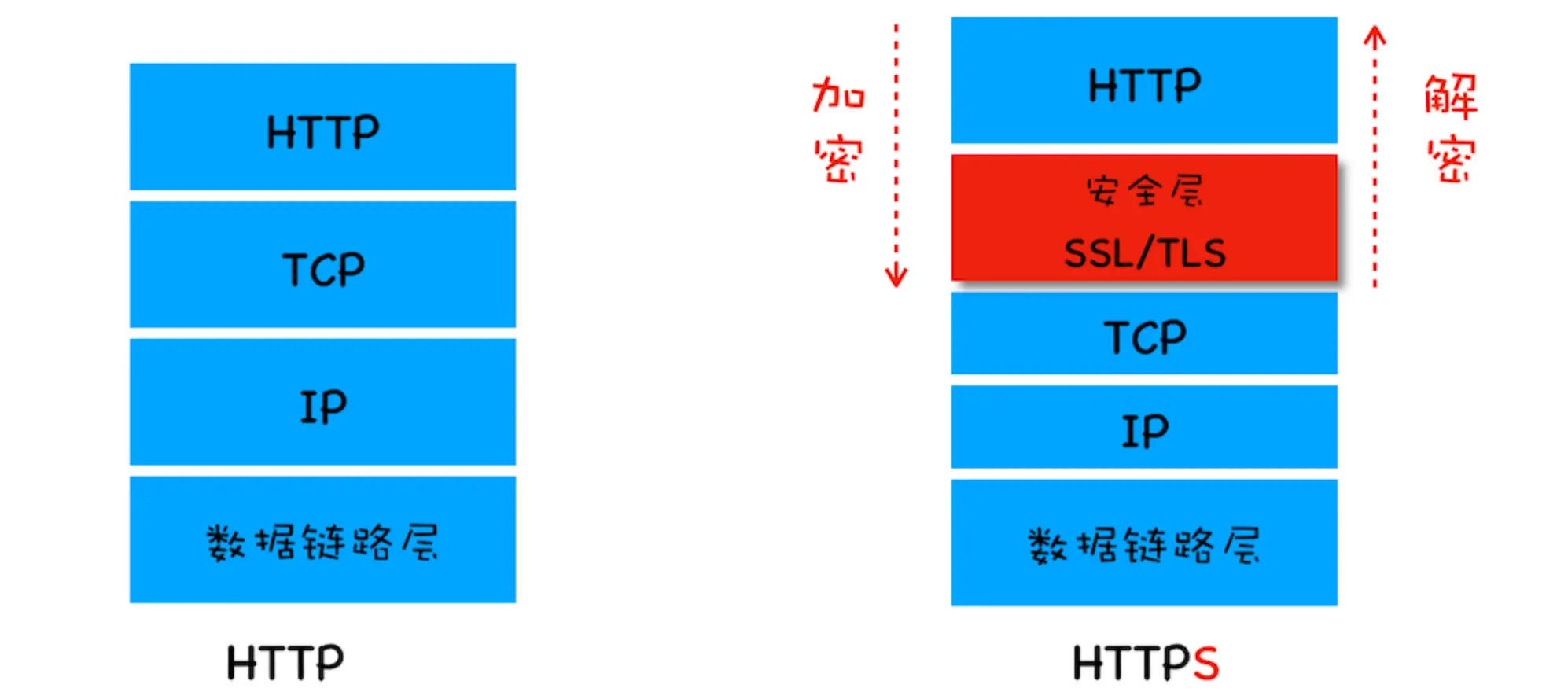
安全层有两个主要的职责:对发起 HTTP 请求的数据进行 加密操作和对接收到 HTTP 的内容进行 解密操作。
https 流程
- 服务器将域名和服务器的公钥交给 ca 认证机构进行数字签名(ca 认证机构专有的私钥)得到数字证书
- 客户端输入 url,然后进行域名解析得到服务器的 ip 地址,进行 tcp 三次握手建立连接,客户端根据协议判断当前域名是 https 的话,就不会直接建立 http 连接,而是在此 tcp 连接的基础上进行 SSL/TLS 握手:向服务器发起数字证书预请求
- 服务器将数字证书发送给客户端
- 客户端会根据当前时间判断证书有没有过期,没有过期则将使用内嵌在操作系统的 ca 认证公钥来解密判断证书的有效性(非对称加密 ca 公钥解密数字证书【ca 机构私钥加密】)
- 如果证书有效,客户端则解密获取到证书中的服务器公钥和域名
- 客户端根据服务器公钥来加密一个密钥发送给服务器,服务器收到之后用服务器的私钥进行解密得到密钥,往后客户端和服务端的通信都是通过这个密钥来进行加密和解密(对称加密)
而如果要在开发环境模拟 https 的流程的话,比如前端项目在本地进行 node 服务器部署的话,vite 项目需要用 vite 来配置 node 服务器私钥和数字证书,如下:
// 这个key是服务器私钥 也是假的,只是给测试环境用,不然的话就是服务器私钥泄露了,真正的服务器私钥是
// 只保存在后台服务器,安全性
export default {
server: {
https: {
key: fs.readFileSync('/path/to/your/key.pem'), // 放置在public中的一个文件
cert: fs.readFileSync('/path/to/your/cert.pem'), // 放置在public中的一个文件中
},
},
};这样客户端发起 ssl/tls 握手的时候,node 服务器会将 vite 配置好的数字证书(如上的 cert)发送给客户端,客户端在验证证书的时效性之后再通过内嵌的 ca 公钥进行解密的到服务器公钥,然后用服务器公钥加密一个对称密钥发给 node 服务器,node 服务器再用 vite 中配置的服务器私钥(如上的 key)进行解密的到对称密钥,往后就都通过对称加密进行传输