编译器

vue 模版编译的流程
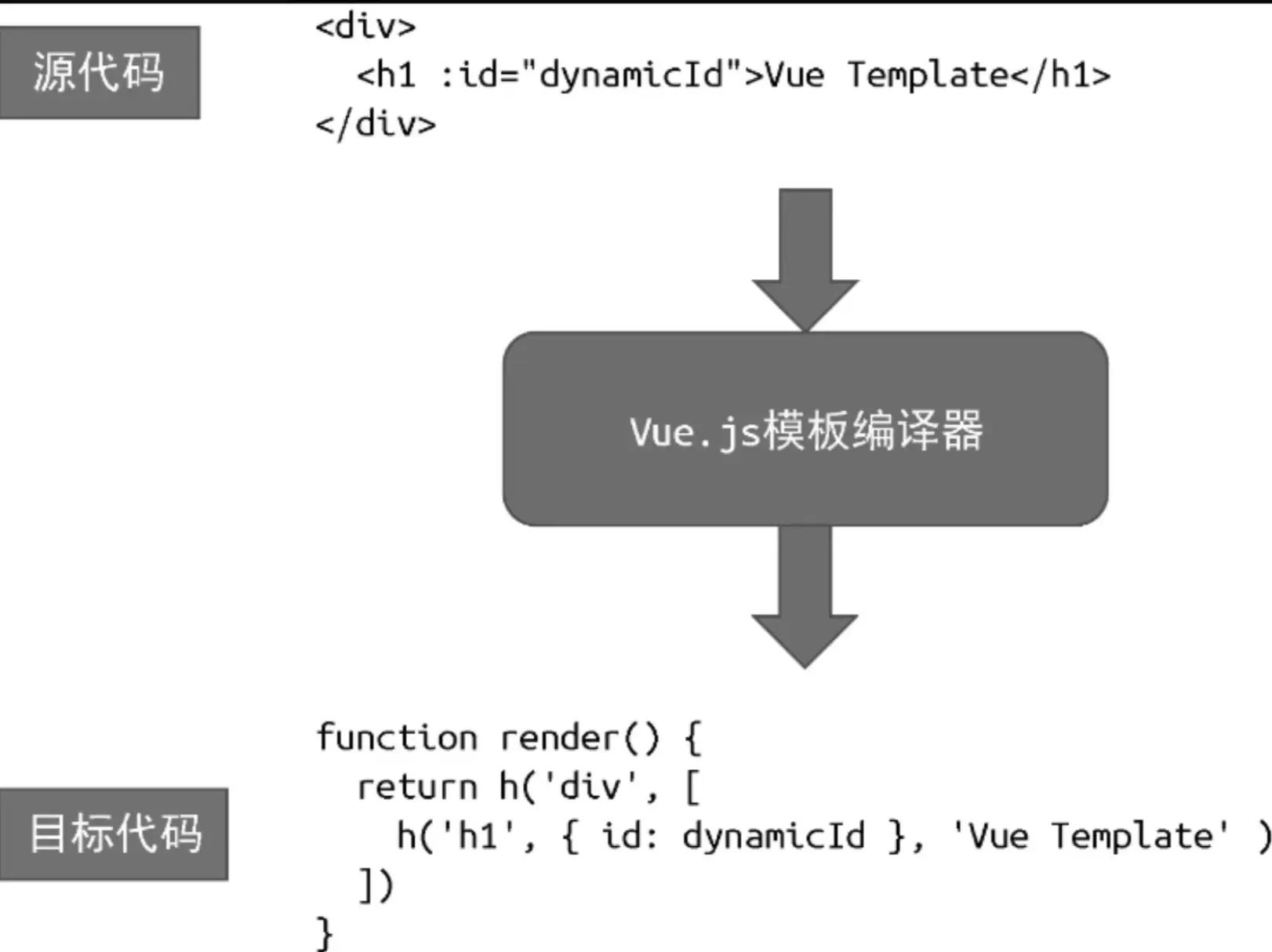
Vue.js 模板编译器的目标代码其实就是渲染函数。详细而言,Vue.js 模板编译器会首先对模板进行词法分析和语法分析,得到模板 AST。接着,将模板 AST 转换(transform)成 JavaScript AST。最后,根据 JavaScript AST 生成 JavaScript 代码,即渲染函数代码。以下给出了 Vue.js 模板编译器的工作流程。
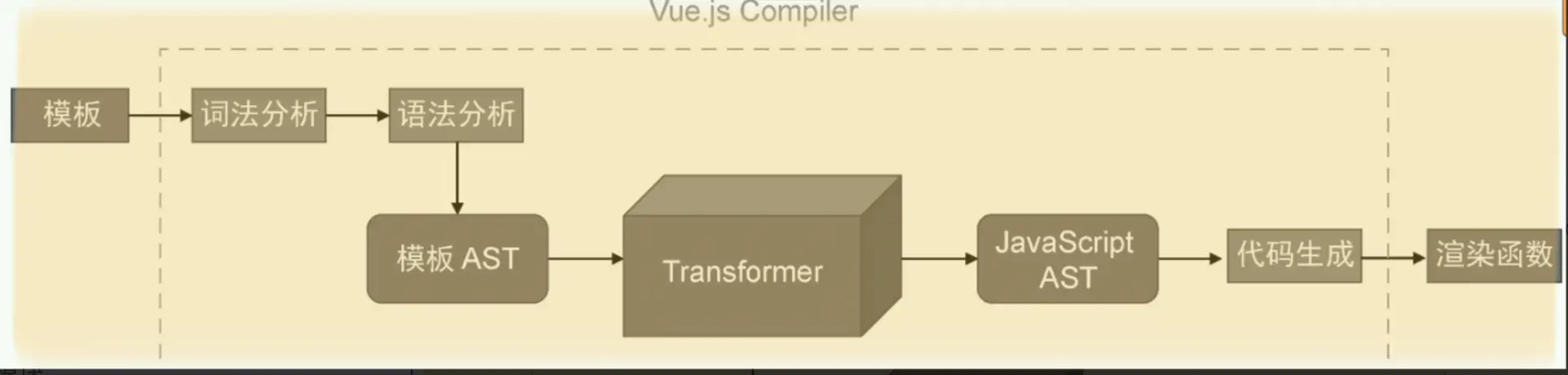
工作流程大致分为三个步骤。
- 分析模板,将其解析为模板 AST。
- 将模板 AST 转换为用于描述渲染函数的 JavaScript AST。
- 根据 JavaScript AST 生成 render 渲染函数代码。
形象比喻:
- ast 是骨架
- jsAst 是能调动骨架运行的肌肉
- render 渲染函数代码是为其注入血液 就此模板摇身一变成了大活人。
遍历 AST 方法
深度优先搜索算法
遍历子节点,把当前节点对应的索引作为转换上下文对象 context 的 childIndex,并对节点进行处理,context.parent 是当前子结点的父节点
function traverseNode(ast, context) {
// 设置当前转换的节点信息 context.currentNode
context.currentNode = ast;
const transforms = context.nodeTransforms;
for (let i = 0; i < transforms.length; i++) {
transforms[i](context.currentNode, context);
}
const children = context.currentNode.children;
if (children) {
for (let i = 0; i < children.length; i++) {
// 递归地调用 traverseNode 转换子节点之前,将当前节点设置为父节点
context.parent = context.currentNode;
// 设置位置索引
context.childIndex = i;
// 递归地调用时,将 context 透传
traverseNode(children[i], context);
}
}
}为什么要采用深度优先搜索算法?广度优先不行吗?
深度优先搜索算法有回溯的过程,先遍历处理子节点再处理父节点,符合处理 ast 树的原理,因为子节点会影响父节点,所以用深度优先搜索算法先处理子节点再处理父节点
例子:
条件渲染的内容 假设我们有一个条件渲染的
<div>
{{#if condition}}
<p>条件为真时显示的内容</p>
{{else}}
<p>条件为假时显示的内容</p>
{{/if}}
</div>转换需求:我们需要根据 condition 的值来选择性地渲染内容。
处理过程:
- 首先,我们处理条件判断的子节点
<p>。如果 condition 为真,则转换出: 条件为真时显示的内容 - 如果 condition 为真,则转换出: 条件为真时显示的内容 如果 condition 为假,则转换出: 条件为假时显示的内容
- 最后,对
<div>的转换要依赖于判断的结果:
<div>
<p>条件为真时显示的内容</p>
</div>或者
<div>
<p>条件为假时显示的内容</p>
</div>在这个例子中,<div> 的内容展示依赖于子 <p>的转换结果,只能在子节点处理完成后进行。
为什么 transform 转换模版 AST 所使用的插件需要在退出阶段执行?
退出阶段的回调函数是反序执行的设计,使得在处理节点时可以考虑到之前处理过的节点的状态。这是因为,当我们从一个节点回溯到它的父节点时,我们可以确保所有子节点的转换逻辑已经执行完毕,这样父节点在执行自己的退出阶段逻辑时,可以根据子节点的最终状态来做出决策。
例如,如果有两个转换函数 transformA 和 transformB,并且 transformA 先于 transformB 注册,那么在遍历和转换过程中,transformB 的退出阶段会先于 transformA 的退出阶段执行。这样的顺序确保了 transformA 在执行其退出阶段逻辑时,可以依赖于 transformB 对节点或其子节点所做的任何修改。
模版编译代码
export function baseCompile(template, options) {
// 1. 先把 template 也就是字符串 parse 成 ast
const ast = baseParse(template);
// 2. 给 ast 加点料(- -#)
transform(
ast,
Object.assign(options, {
nodeTransforms: [transformElement, transformText, transformExpression],
})
);
// 3. 生成 render 函数代码
return generate(ast);
}模板字符串 -- parse(模版字符串) --> 模版 AST ---transform(模版 AST)---> javascriptAST -----generate(JS AST)-----> render 渲染函数
parse 模块
所谓 parse 模块,即对模版字符串进行解析并生成模版 AST
首先进行模版解析 parse 之前,会创建一个 parse 的上下文对象 context,这个 contex 对象里面的 source 字段用来存储模板字符串的内容,后续消费模版字符串都是消费 context.source
// 生成ast抽象语法树
export function baseParse(content: string) {
// 生成parse上下文对象
const context = createParserContext(content);
// createRoot创建根节点即ast节点---> root parseChildren是解析模版字符串的内容,这些内容都是root根节点的子节点
return createRoot(parseChildren(context, []));
}
/**
创建parse上下文对象
*/
function createParserContext(content) {
return {
source: content, // 模版字符串的内容
};
}以下是 parseChildren 的内容,是来解析 template 模版字符串内容的,解析消费完成之后生成对应的 ast 节点

解析之后生成的 ast 节点的祖宗节点是 root,这是一开始就约定好的。
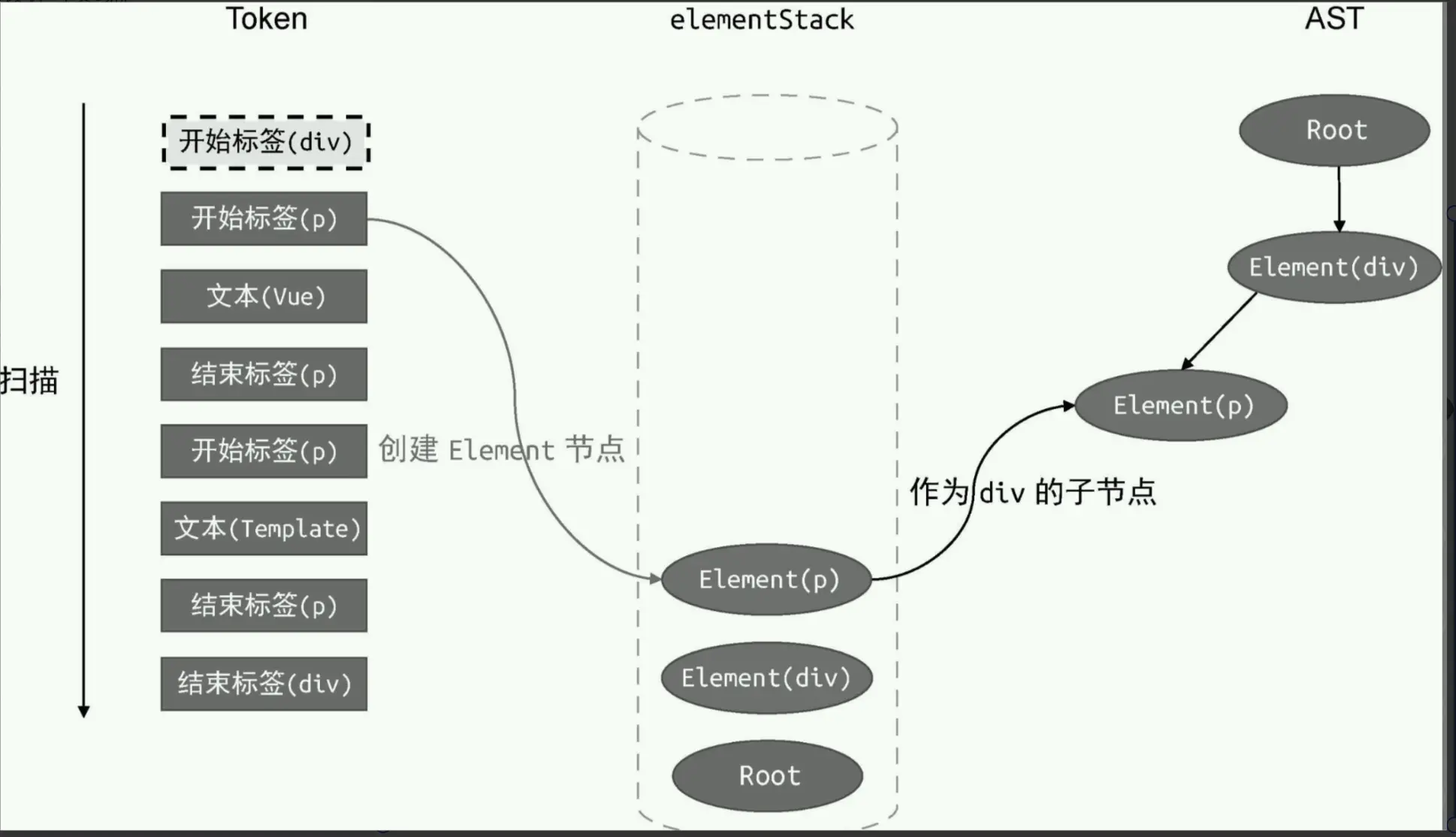
解析 element
维护一个栈 ancestors,每遍历到元素节点即进行压栈处理,然后递归调用 parseChildren 解析当前元素节点的子元素,然后把栈 ancestors 也传递过去,栈顶即当前遍历到的节点的父节点,根据这个将遍历到的子节点生成对应的 ast 节点后挂载到当前栈顶节点下
parseTag
就是消费掉模版字符串,然后生成对应的 ast 标签节点
function parseTag(context: any, type: TagType): any {
// 发现如果不是 > 的话,那么就把字符都收集起来 ->div
// 正则
const match: any = /^<\/?([a-z][^\r\n\t\f />]*)/i.exec(context.source);
const tag = match[1];
// 移动光标
// <div
advanceBy(context, match[0].length);
// 暂时不处理 selfClose 标签的情况 ,所以可以直接 advanceBy 1个坐标 < 的下一个就是 >
advanceBy(context, 1);
if (type === TagType.End) return;
let tagType = ElementTypes.ELEMENT;
return {
type: NodeTypes.ELEMENT,
tag,
tagType,
};
}解析插值表达式
parseInterpolation 方法只是解析插值表达式的内容而已,,将中间内容取出来并生成对应的 ast 节点
解析文本
找到解析文本的结束索引,遍历结束 tokens 数组,看当前模版字符串中找到的第一个结束索引,找到之后文本截取最长则是在这个结束索引之前,最后消费掉模版字符串之后生成对应的文本 ast 节点

总结:parse
开启有限状态机 遍历模板字符串,遇到元素字符串就消费字符串并生成对应的 ast 节点,然后进行压栈,再遍历其子节点(此时遍历的子节点的父节点为栈顶节点),将子节点生成对应的 ast 节点并挂载到当前父 ast 节点下,以此类推,最终生成 ast 抽象语法树
有限状态机
所谓“有限状态”,就是指有限个状态,而‘自动机’意味这随着字符的输入,解析器会自动地在不同状态间迁移。模版解析 parse 用的就是有限状态机原理来解析的,通过有限状态机将模版解析成模版 AST
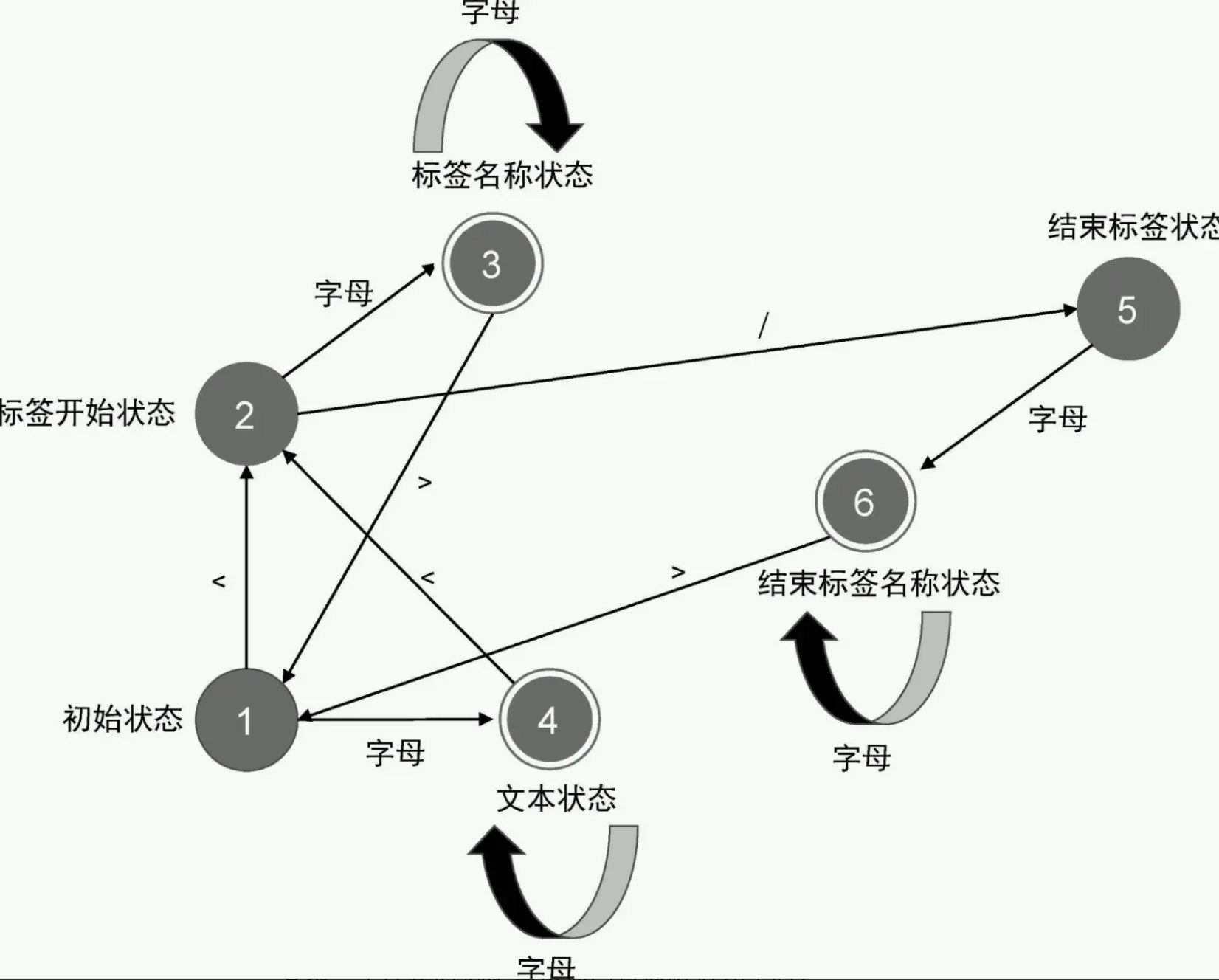
状态机的停止时机,具体如下: ● 第一个停止时机是当模板内容被解析完毕时; ● 第二个停止时机则是在遇到结束标签时,这时解析器会取得父级节点栈栈顶的节点作为父节点,检查该结束标签是否与父节点的标签同名,如果相同,则状态机停止运行。
/**
* 是否结束当前状态机 每次parseChildren都会开启一个新的状态机 判断当前状态机是否结束的标志是:看当前模版字符串的开头是否在当前栈中有对应的标签,如果有,说明当前状态机应该要结束了 如</ div>
* @param context
* @param ancestors
* @returns
*/
function isEnd(context: any, ancestors) {
// 检测标签的节点
// 如果是结束标签的话,需要看看之前有没有开始标签,如果有的话,那么也应该结束
// 这里的一个 edge case 是 <div><span></div>
// 像这种情况下,其实就应该报错
const s = context.source;
if (context.source.startsWith("</")) {
// 从后面往前面查
// 因为便签如果存在的话 应该是 ancestors 最后一个元素
for (let i = ancestors.length - 1; i >= 0; --i) {
if (startsWithEndTagOpen(s, ancestors[i].tag)) {
return true;
}
}
}解析道元素标签即压栈,并生成对应的 ast 节点,然后遍历其子节点,生成对应的 ast 节点挂载到当前栈顶节点对应的 ast 节点下面
transForm 模块
所谓 transform 模块,即对生成的模版 ast 进行转换,最后生成 js AST,js AST 是用来生成 js 代码 render 函数的
/**
* 将模版ast进行转换
* @param root 模版ast的root
* @param options 转换插件
*/
function transform(root, options = {}) {
// 1. 创建 context
const context = createTransformContext(root, options);
// 2. 遍历 node 这里面会使用插件对ast树进行操作节点,转换节点后的生成的新ast节点存储到原来ast树node节点的codegen属性中
traverseNode(root, context);
// 3. 从模版ast节点中的codegen属性中取出新ast节点 ---> 生成js AST
createRootCodegen(root, context);
root.helpers.push(...context.helpers.keys());
}- 首先第一步是生成 transform 模块的执行上下文 context,将转换插件内容 option 赋值到执行上下文中等操作,完善整个转换模版 ast 中所需要的数据
/**
* 创建Transform执行上下文对象
* @param root 根节点
* @param options 转换的插件 比如要把元素节点对象的内容进行修改,或者对清除掉原有ast树中的文本节点等插件功能
* @returns
*/
function createTransformContext(root, options): any {
const context = {
root,
nodeTransforms: options.nodeTransforms || [],
helpers: new Map(),
helper(name) {
// 这里会收集调用的次数
// 收集次数是为了给删除做处理的, (当只有 count 为0 的时候才需要真的删除掉)
// helpers 数据会在后续生成代码的时候用到
const count = context.helpers.get(name) || 0;
context.helpers.set(name, count + 1);
},
};
return context;
}- 使用深度优先搜索算法遍历模版 AST 树, 使用赋值到 transform 执行上下文中的插件对遍历到的模版 AST 节点进行转换,转换节点后生成的新 ast 节点存储到模版 AST 树节点的 codegenNode 属性中,所以并不是完全生成一颗全新的 ast 树,而是在对模版 ast 的 node 节点进行转换操作生成新的 js node 节点赋值给当前操作的 node 节点的 codegenNode 属性,后续根据 js AST 生成 js 代码其实是遍历模版 ast 节点中的 codegenNode 属性值来获取 js node 信息,从而生成对应的 js 代码 render 函数
function traverseNode(node: any, context) {
const type: NodeTypes = node.type;
// 遍历调用所有的 nodeTransforms
// 把 node 给到 transform
// 用户可以对 node 做处理
const nodeTransforms = context.nodeTransforms;
const exitFns: any = [];
for (let i = 0; i < nodeTransforms.length; i++) {
const transform = nodeTransforms[i];
const onExit = transform(node, context);
if (onExit) {
exitFns.push(onExit);
}
}
switch (type) {
case NodeTypes.INTERPOLATION:
// 插值的点,在于后续生成 render 代码的时候是获取变量的值
context.helper(TO_DISPLAY_STRING);
break;
case NodeTypes.ROOT:
case NodeTypes.ELEMENT:
transformElement(node, context);
break;
default:
break;
}
// 3. 处理插值
// 先处理完子节点,然后回溯之后再处理当前这个父节点,因为子节点的内容影响到父节点
let i = exitFns.length;
// i-- 这个很巧妙
// 使用 while 是要比 for 快 (可以使用 https://jsbench.me/ 来测试一下)
while (i--) {
exitFns[i]();
}
}以上的 context.nodeTransforms 是转换过程中所需要的插件集合
如:transformElement 插件:对遍历到的 ast 元素节点进行操作,每转换一个模版 ast 节点就生成一个新的 JS node 节点赋值给当前操作的 ast 节点的 codegenNode 属性
function transformElement(node, context) {
if (node.type === NodeTypes.ELEMENT) {
return () => {
const vnodeTag = `'${node.tag}'`;
const vnodeProps = null;
let vnodeChildren = null;
if (node.children.length > 0) {
if (node.children.length === 1) {
// 只有一个孩子节点 ,那么当生成 render 函数的时候就不用 [] 包裹
const child = node.children[0];
vnodeChildren = child;
}
}
// 创建一个新的 node 用于 codegen 的时候使用
node.codegenNode = createVNodeCall(
context,
vnodeTag,
vnodeProps,
vnodeChildren
);
};
}
}当前 ast 节点的插件执行(transform 转换)的时机是在子节点均 transform 转换完毕之后才会执行
- 创建根 rootCodegen,取出的 codegenNode 属性值赋值给 root 的 codegenNode 属性,这个就是 js AST,用来生成 js 代码 render 函数的
function createRootCodegen(root: any, context: any) {
const { children } = root;
// 只支持有一个根节点
// 并且还是一个 single text node
const child = children[0];
// 如果是 element 类型的话 , 那么我们需要把它的 codegenNode 赋值给 root
// root 其实是个空的什么数据都没有的节点
// 所以这里需要额外的处理 codegenNode
// codegenNode 的目的是专门为了 codegen 准备的 为的就是和 ast 的 node 分离开
if (child.type === NodeTypes.ELEMENT && child.codegenNode) {
const codegenNode = child.codegenNode;
root.codegenNode = codegenNode;
} else {
root.codegenNode = child;
}codegen 模块
codegen 模块即根据 JS AST 来 generate 生成 render 函数的
- 首先第一步先创建 codegen 模块的执行上下文,存储 generate 过程所需要的全局变量和方法(比如拼接 render 函数字符串的方法、换行的方法等)
/**
根据js AST生成js代码render函数
*/
export function generate(ast, options = {}) {
// 先生成 context
const context = createCodegenContext(ast, options);
return {
code: context.code,
};/**
* 它接受一个 AST 和配置对象作为参数。这个函数主要用于创建一个上下文对象,用于生成代码。
* @param ast
* @param param1
* @returns
*/
function createCodegenContext(
ast: any,
{ runtimeModuleName = 'vue', runtimeGlobalName = 'Vue', mode = 'function' }
): any {
// 创建一个上下文对象
const context = {
code: '',
mode,
runtimeModuleName,
runtimeGlobalName,
helper(key) {
return `_${helperNameMap[key]}`;
},
push(code) {
context.code += code;
},
newline() {
context.code += '\n';
},
};
return context;
}- 根据模版 ast 节点的 codegenNode 属性值(即 JS AST 节点)进行 genNode(ast.codegenNode, context),根据不同的 js ast 节点生成不同的代码字符串,最终生成 render 函数字符串
function genNode(node: any, context: any) {
// 生成代码的规则就是读取 node ,然后基于不同的 node 来生成对应的代码块
// 然后就是把代码快给拼接到一起就可以了
switch (node.type) {
case NodeTypes.INTERPOLATION:
genInterpolation(node, context);
break;
case NodeTypes.SIMPLE_EXPRESSION:
genExpression(node, context);
break;
case NodeTypes.ELEMENT:
genElement(node, context);
break;
case NodeTypes.COMPOUND_EXPRESSION:
genCompoundExpression(node, context);
break;
case NodeTypes.TEXT:
genText(node, context);
break;
default:
break;
}
}generate 完整代码
export function generate(ast, options = {}) {
// 先生成 context
const context = createCodegenContext(ast, options);
const { push, mode } = context;
// 1. 先生成 preambleContext
if (mode === 'module') {
genModulePreamble(ast, context);
} else {
genFunctionPreamble(ast, context);
}
const functionName = 'render';
const args = ['_ctx'];
// _ctx,aaa,bbb,ccc
// 需要把 args 处理成 上面的 string
const signature = args.join(', ');
push(`function ${functionName}(${signature}) {`);
// 这里需要生成具体的代码内容
// 开始生成 vnode tree 的表达式
push('return ');
genNode(ast.codegenNode, context);
push('}');
return {
code: context.code,
};
}总结: 模版编译首先进行 parse 解析生成模版 AST,然后再通过插件转换模版 AST 生成 JS AST,最后根据 JS AST 生成 js 代码 render 渲染函数